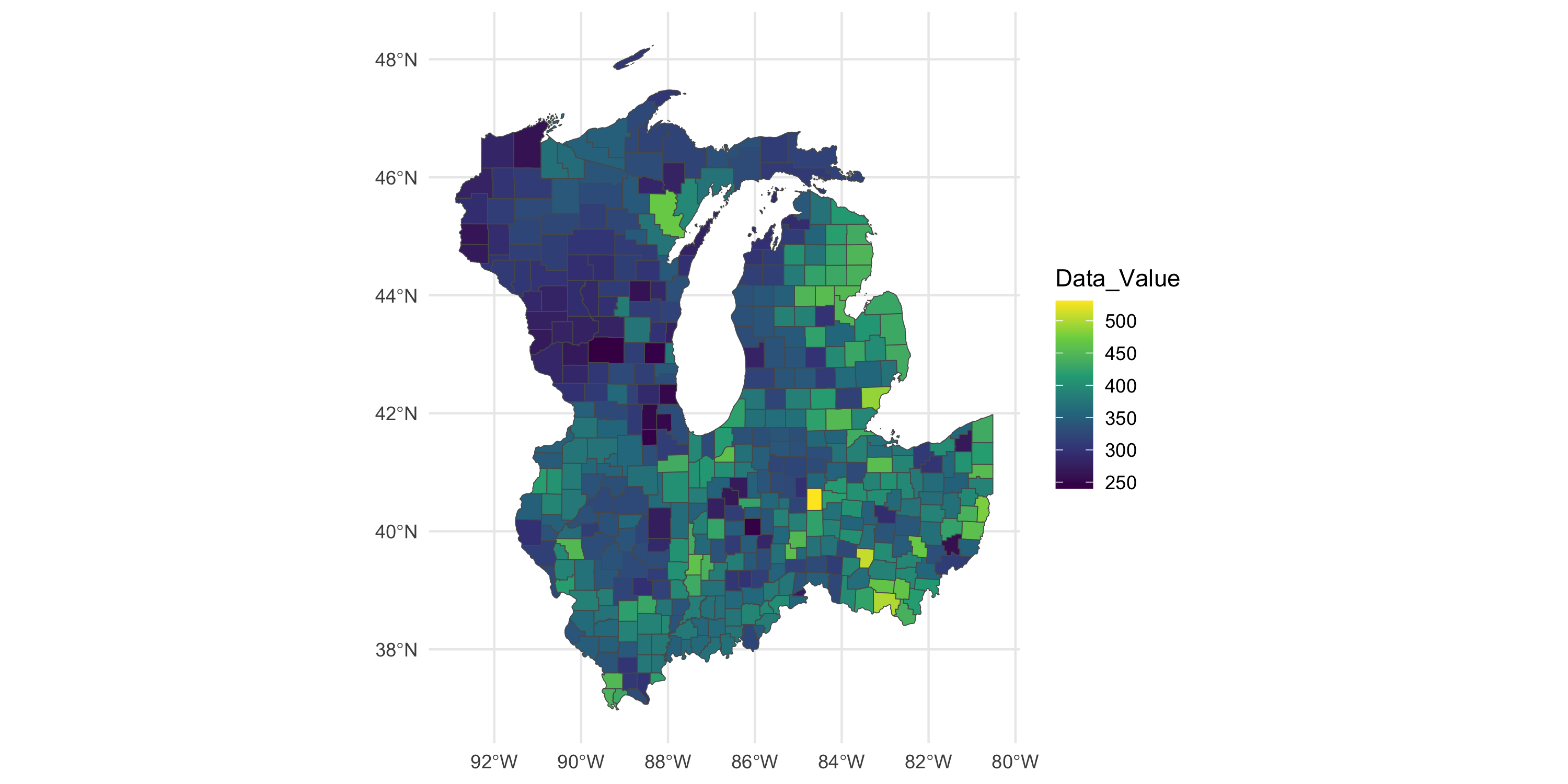
Moran I test under randomisation
data: df_local$Data_Value
weights: lw
Moran I statistic standard deviate = 15.968, p-value < 2.2e-16
alternative hypothesis: two.sided
sample estimates:
Moran I statistic Expectation Variance
0.4687127949 -0.0022935780 0.0008700179
Conditionally Autoregressive (CAR) models
Let Y_i be our data at areal unit i
We assume Y_i | Y_j, j\neq i \sim N\left(\sum_{j}b_{ij} y_{j}, \tau^2_i \right)\quad i=1,\dots,n
We apply Brook’s lemma (see book p. 78) to find the joint density from all the full conditionals
We obtain
Y \sim N(0, (I-B)^{-1}D )
B is the matrix of b_{ij} and D is diagonal with elements d_{ii}=\tau^2_i
Here, the sum \sum_{j: j\sim i} means we are summing over all the neighbors of i. Notice \sum_{j: j\sim i} w_{ij} = \sum_j b_{ij} w_{ij} using our definition of B
ICAR model
A property of this model is that we can write the joint density as a function of all pairwise differences
Moran I test under randomisation
data: model_residuals
weights: lw
Moran I statistic standard deviate = -5.1855, p-value = 2.154e-07
alternative hypothesis: two.sided
sample estimates:
Moran I statistic Expectation Variance
-0.1548429467 -0.0022935780 0.0008654362
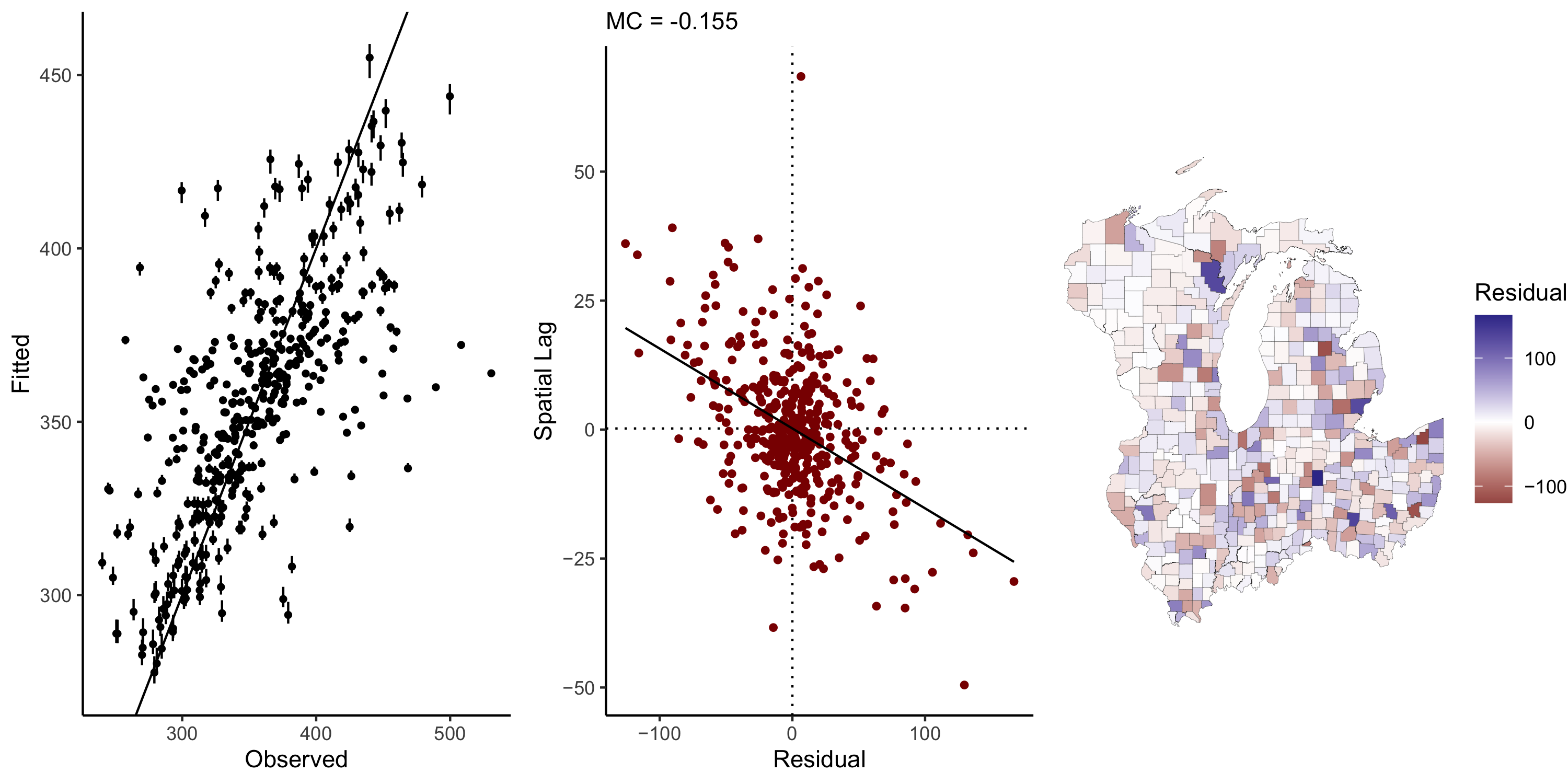
In this case there is still spatial dependence in the residuals
We did not use any covariates
One worry we should have: do we need an offset?
Offset: an additive or multiplicative constant that adjusts the observed value by the size of the relative area
For example, if we were counting the absolute number of cases, we should offset by population
Not doing so may result in a residual pattern that looks just like the area size!
In the heart disease case we have data per 100k population so we do not need offsets
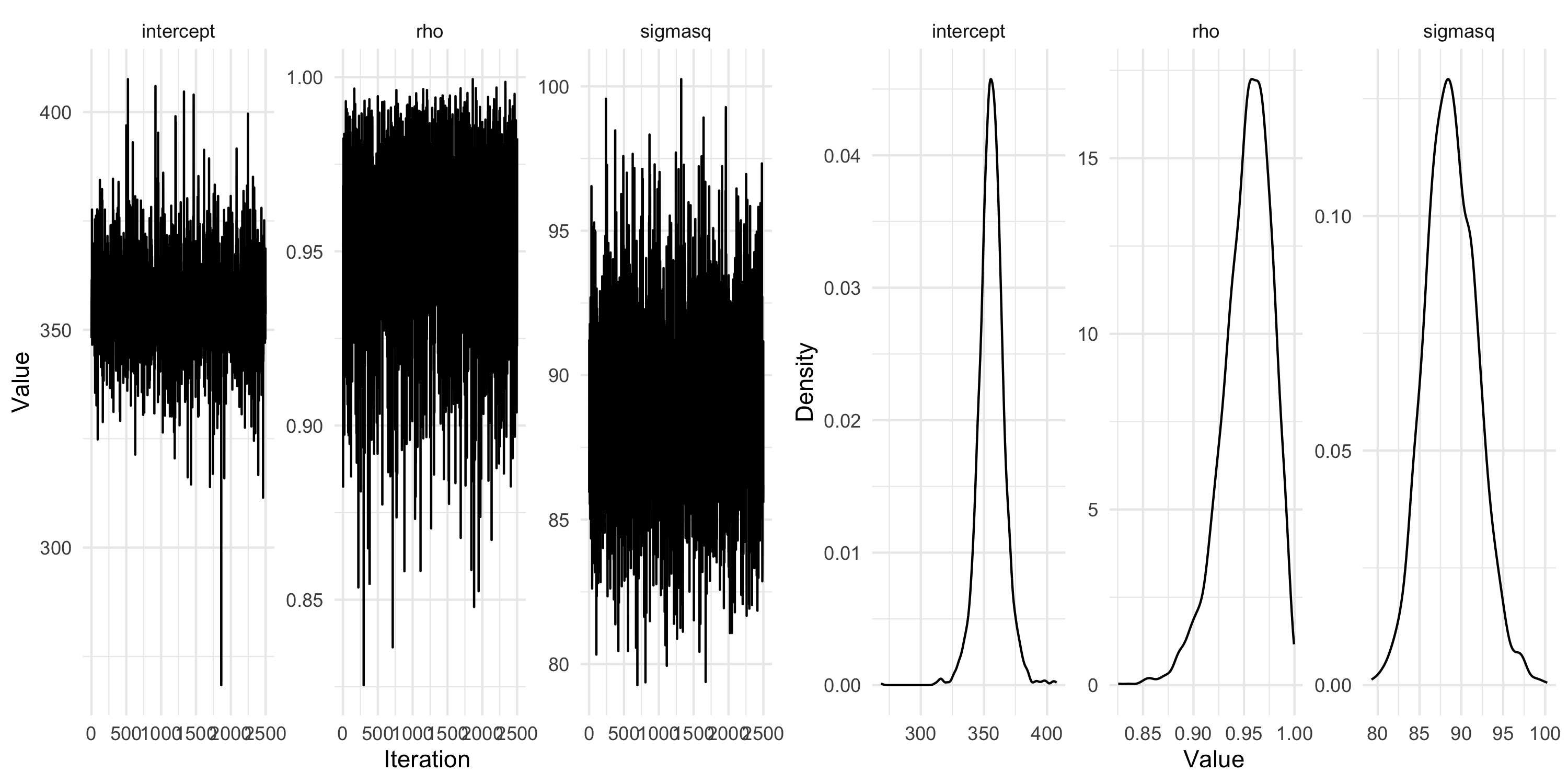
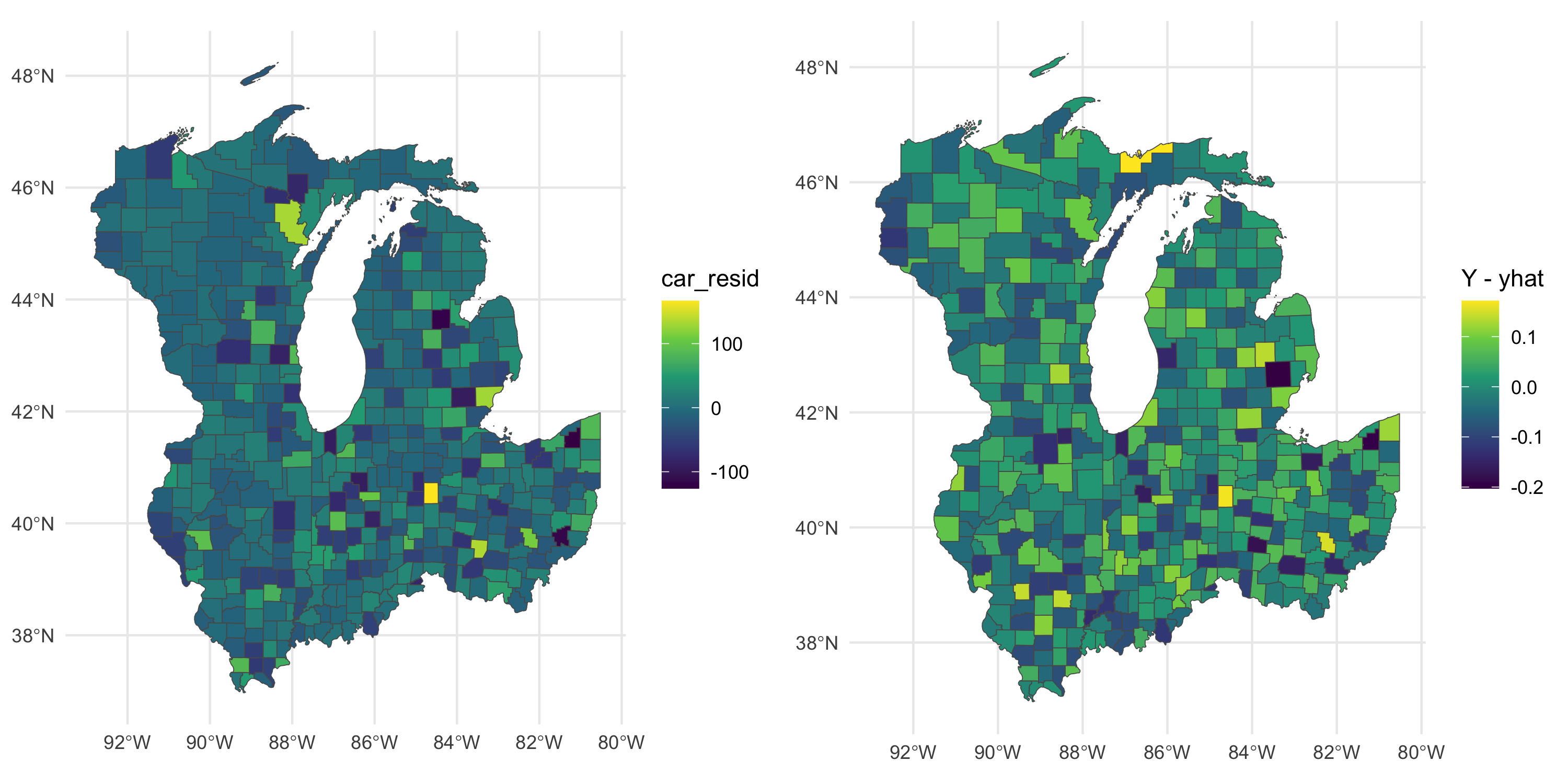
Fitting a CAR model using geostan
The model we saw did not allow for the introduction of measurement error
We thus fit a CAR model to the data directly
geostan seems to lack the ability to fit a latent model to Gaussian data
Simultaneously Autoregressive models (SAR)
In this case we model all outcomes Y as arising from independent innovations:
Define B as earlier as a weight matrix, possibly binary
Define R as diagonal with region-specific diagonal entries r_{ii}
Moran I test under randomisation
data: Y - yhat
weights: lw
Moran I statistic standard deviate = -3.4487, p-value = 0.0005634
alternative hypothesis: two.sided
sample estimates:
Moran I statistic Expectation Variance
-0.1040171021 -0.0022935780 0.0008700435
We have spatial information about the spatial occurence of some event
We are mostly interested with learning about the pattern of locations
Where did the events occur?
The dataset this gives rise to is a pattern of locations (points)
Our dataset boils down to the set of observed locations \{ S_1, \dots, S_n \}
We model these locations as random
If we were also interested on other information about the events we would talk of a marked point pattern. In that case both \{ S_1, \dots, S_n \} and \{Y(S_1), \dots, Y(S_n)\} are random
Recall with point-referenced data we only model \{Y(s_1), \dots, Y(s_n)\} assuming the locations are not random (i.e. known, fixed, constant)
Areal data as aggregates of point patterns
Suppose we want to model the spread of a disease
Or the spread of a type of invasive species
Or the occurrence of forest fires
Or the location of traffic accidents
Areal data as aggregates of point patterns
Aggregation into areas
Rather than directly using the dataset of locations, we summarize information across pre-specified areas
Typically, we count how many events occurred in each area
Areal data as aggregates of point patterns
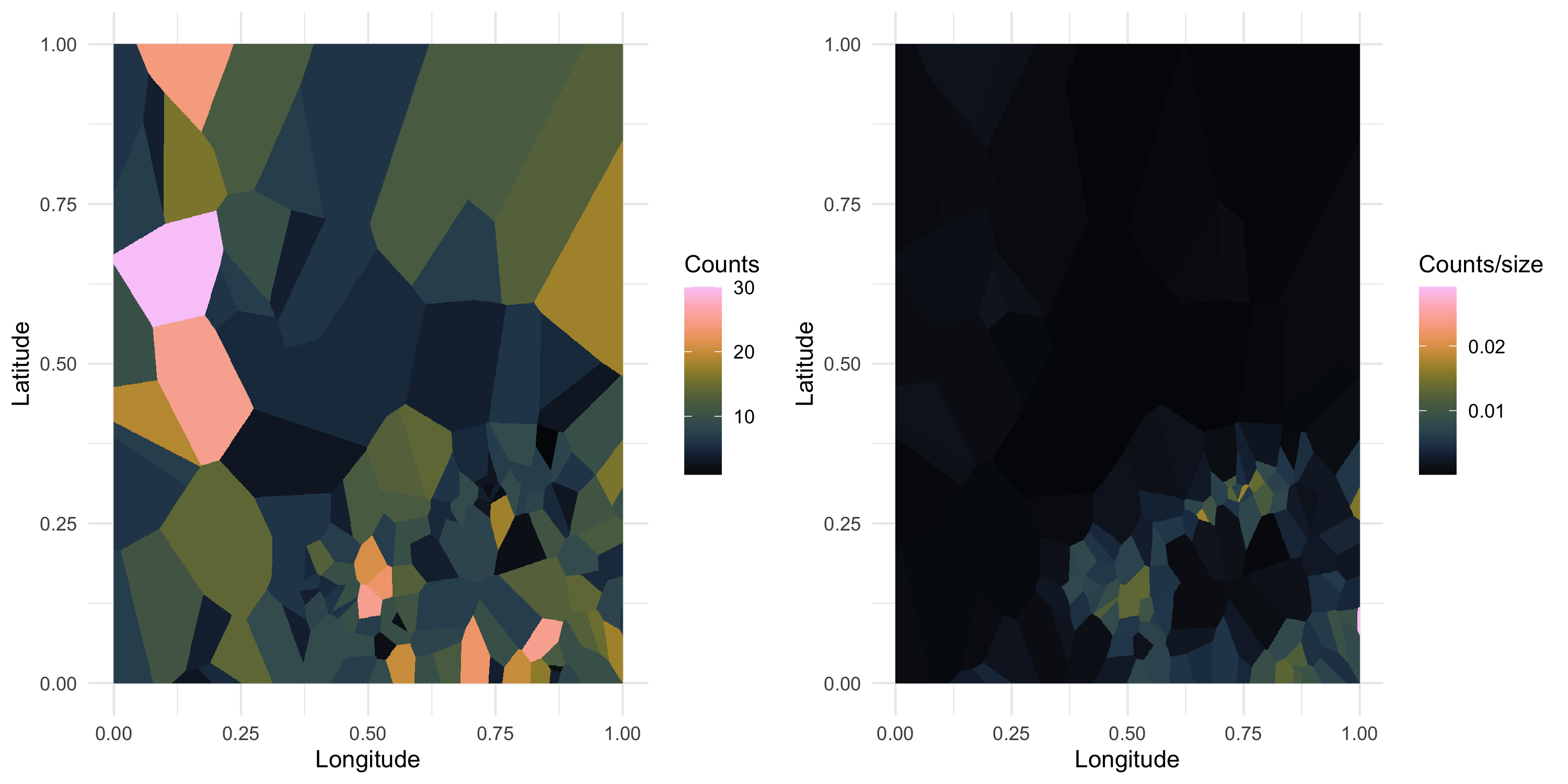
Be mindful of the size of the areas when we count!
Areal data as aggregates of point patterns
Motivation/Scenario 1
In many cases, we only have information at an aggregate level
Even if we have exact location of “disease” we may only have socio-demographic info at zip-county-state level
See book Section 6.4
Motivation/Scenario 2
We are interested in the intensity of the underlying process
Higher intensity means larger rate of occurrence of events
Estimating intensity continuously is a difficult problem in 2+ dimensions
By aggregating, we can simplify (i.e. approximate) and make the problem manageable
See book Section 8 (specifically 8.4.3)
Areal data as aggregates of point patterns
Let’s get modeling!
We have a set of areas or spatial indices or centroids or coordinates \{s_1, \dots, s_n\}
We have counts at those locations: \{ Y_1, \dots, Y_n \} where Y_i=Y(s_i)
Model those counts as Poisson random variables
Set up a spatial GLM model with log link
Call E_i the size of area i. This is problem dependent!
Example: if Y_i are disease counts, E_i should be the expected number of counts
Call n_i the population size at i (not a random variable), then E_i = n_i \cdot \bar{r} where \bar{r} is the overall occurrence rate across the region
Ease of adaptation is often an important part of algorithm choice
Review: Metropolis updates
Recall the general problem of Metropolis-based updates
We want to create a Markov chain \{ X_m \}m\ge 0 that will ultimately converge to a target density p(x) of a random vector X \in \Re^d
To do so, we build a proposal distribution q(\cdot | \cdot) that suggests the next value for X in the chain
At step m, we thus generate X^*_{m+1} \sim q(\cdot | X_{m})
We then accept or reject X^*_{m+1} based on the Hastings ratio
If accepted, we move to X^*_{m+1}, otherwise we do not move. In other words, accept means X_{m+1} = X^*_{m+1}, reject means X_{m+1} = X_{m}
The question is how to choose q(\cdot | \cdot) such that the resulting algorithm is efficient
Example: Random walk Metropolis
Fix r, then let
q(x | x_{\text{old}}) = N(x; x_{\text{old}}, r^2 I_d) In other terms, let u \sim N(0, I_d), we accept/reject the following proposal: x_{\text{prop}} = x_{\text{old}} + r u
We saw this is not very easy to tune and requires at least some adaptation for r
Take the target density p(x) and compute its gradient \nabla p(x)
Fix \varepsilon, then let
q(x | x_{\text{old}}) = N(x; x_{\text{old}} + \frac{\varepsilon^2}{2} \nabla p(x_{\text{old}}), \varepsilon^2 I_d) In other terms, let u \sim N(0, I_d), we accept/reject the following proposal: x_{\text{prop}} = x_{\text{old}} + \frac{\varepsilon^2}{2} \nabla p(x_{\text{old}}) + \varepsilon u This proposal takes into account some local information about the distribution which we ultimately want to sample from
Example: MALA with preconditioner
Take the target density p(x) and compute its gradient \nabla p(x)
Fix \varepsilon and M, then let
q(x | x_{\text{old}}) = N(x; x_{\text{old}} + \frac{\varepsilon^2}{2} M \nabla p(x_{\text{old}}), \varepsilon^2 M) In other terms, let u \sim N(0, I_d), we accept/reject the following proposal: x_{\text{prop}} = x_{\text{old}} + \frac{\varepsilon^2}{2} M \nabla p(x_{\text{old}}) + \varepsilon M^{\frac{1}{2}} u
M^{\frac{1}{2}} is a matrix square root (e.g. Cholesky)
This proposal takes into account some local information about the distribution which we ultimately want to sample from
We can use M to further improve upon MALA but fixing it may be difficult. Alternatively:
M = ( - \nabla^2 p(x_{\text{old}}) )^{-1} (inverse of negative Hessian matrix of the target density) leads to the simplified Riemannian-manifold MALA (Girolami and Calderhead 2010)
M can be adapted using ( - \nabla^2 p(x) )^{-1} leading to a faster and more efficient algorithm in spatial models (P and Dunson 2024)
R package meshed uses MALA with adaptive preconditioner for non-Gaussian spatial models