beta_vals <- seq(-2, 2, length.out=1000)
delta <- diff(beta_vals)[1]
post_vals_unnorm <- beta_vals %>% sapply(\(beta) exp(sum(dpois(y, exp(x*beta), log=TRUE)) + dnorm(beta, log=TRUE)))
post_vals <- post_vals_unnorm/sum(post_vals_unnorm)/delta
df_post <- data.frame(beta=beta_vals, post=post_vals, prior=dnorm(beta_vals)) %>%
tidyr::pivot_longer(cols=c(post,prior))
ggplot(df_post, aes(x=beta, y=value, color=name)) +
labs(color="Distribution") +
geom_line() +
theme_minimal()Some notes on computing for Bayesian models
Spatial Statistics - BIOSTAT 696/896
Setting up Metropolis algorithms
- Let’s consider a simple example in which M-H can be useful
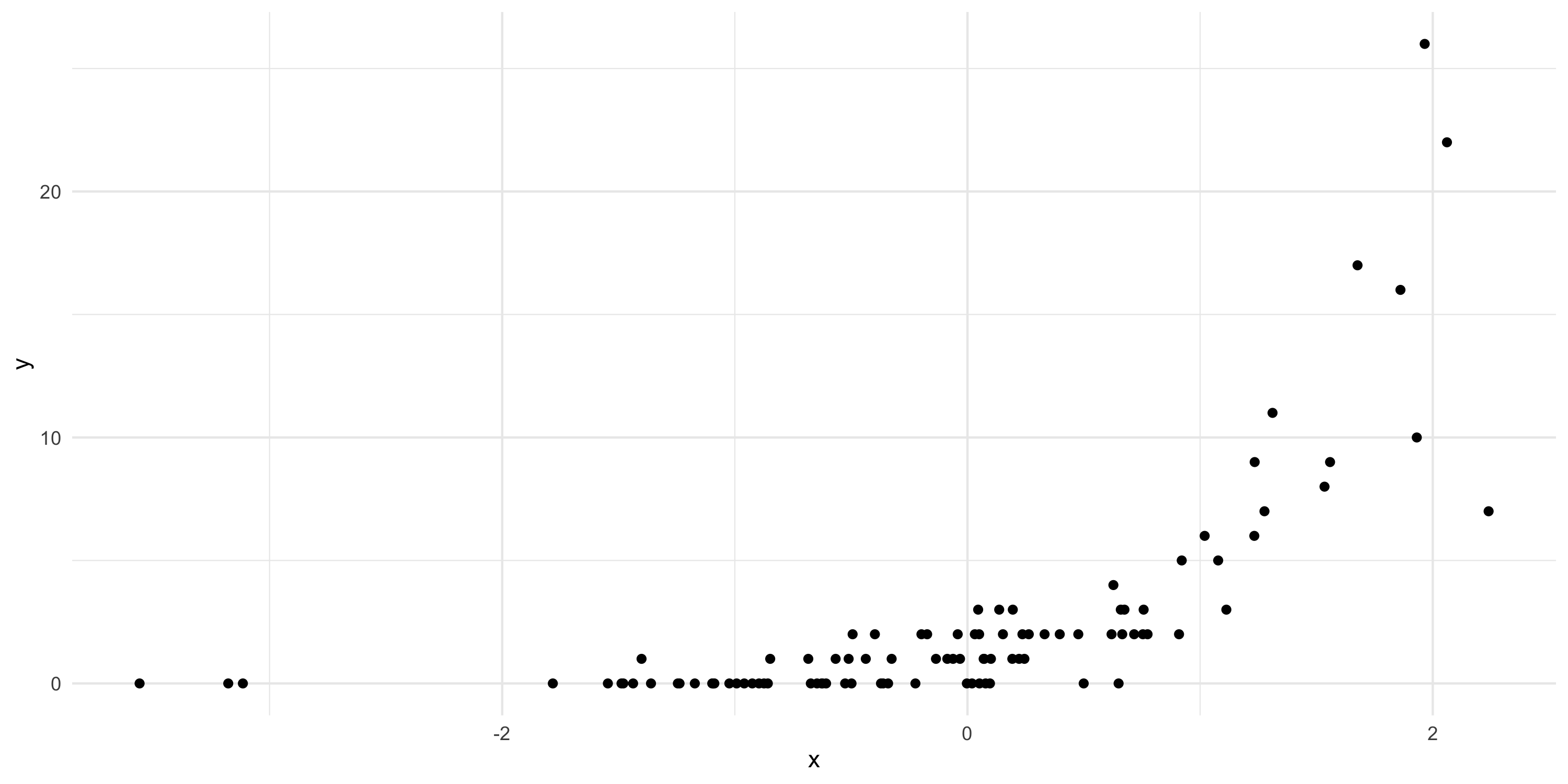
- Assume our model is Y|\beta \sim Poisson(\exp\{ \beta x \}) where x is a covariate
- Assume our prior is \beta \sim N(0, 1)
- Data:
Setting up Metropolis algorithms
- We are looking for the posterior for \beta that is p(\beta | Y)
- p(\beta | Y) = \frac{p(Y | \beta) p(\beta)}{p(Y)} = \frac{p(Y | \beta) p(\beta)}{\int p(Y|\beta) p(\beta) d\beta}
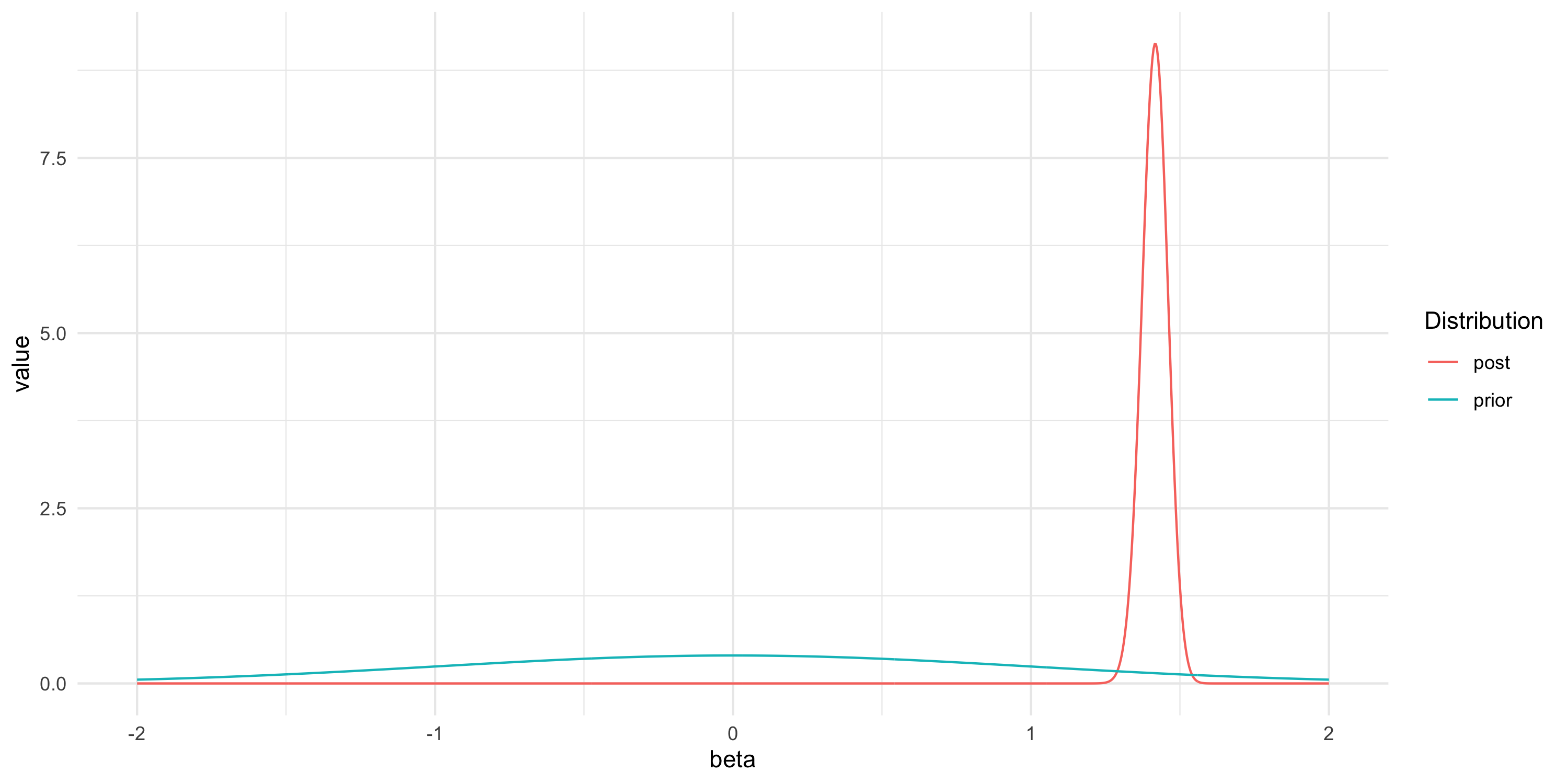
- We can approximate the posterior numerically because this is an extremely simple problem
Setting up Metropolis algorithms
- Comment on this plot. Are you happy with the results? What would you change if not?
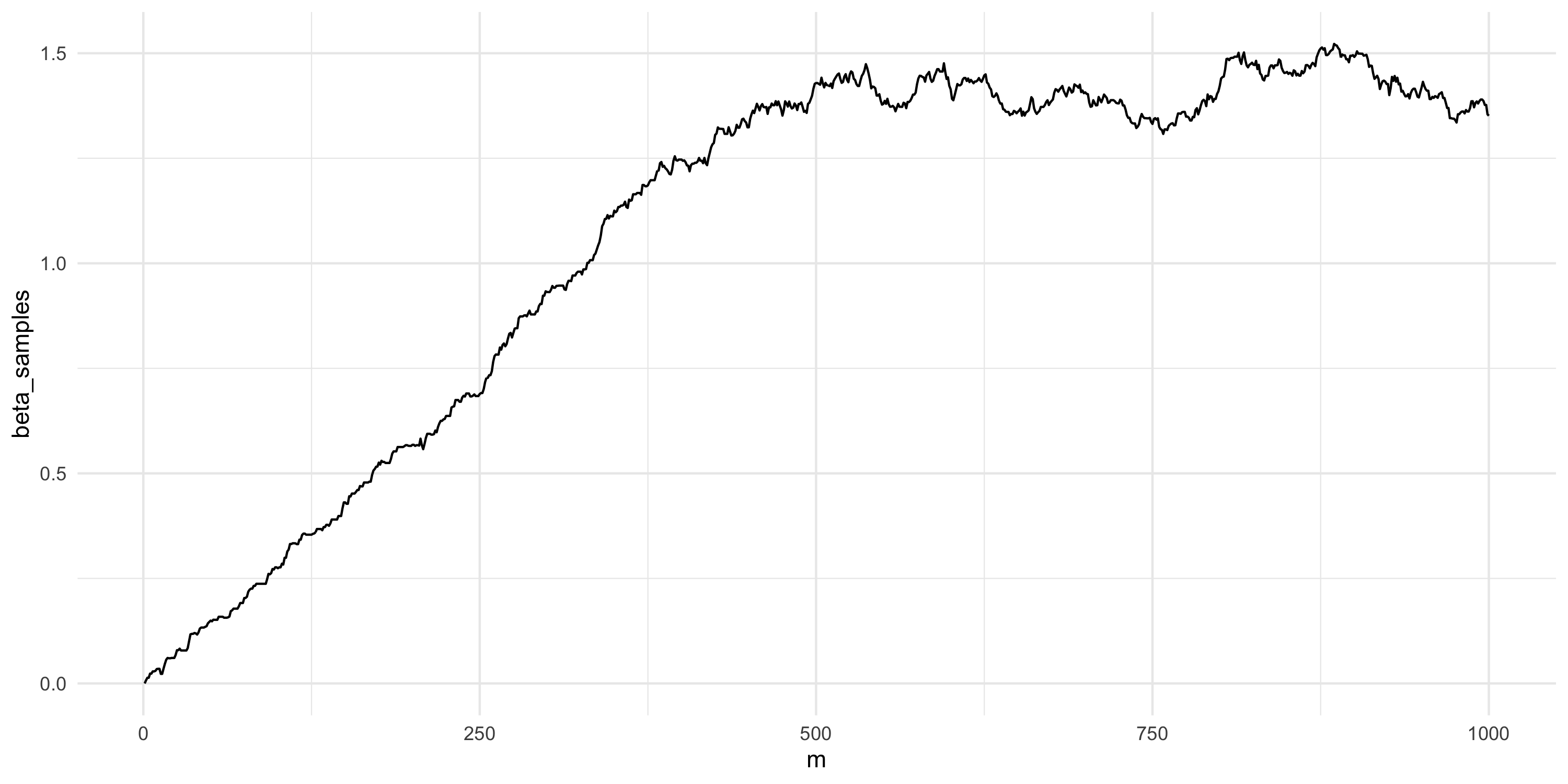
Setting up Metropolis algorithms
- What about now?
Setting up Metropolis algorithms
- What about now?
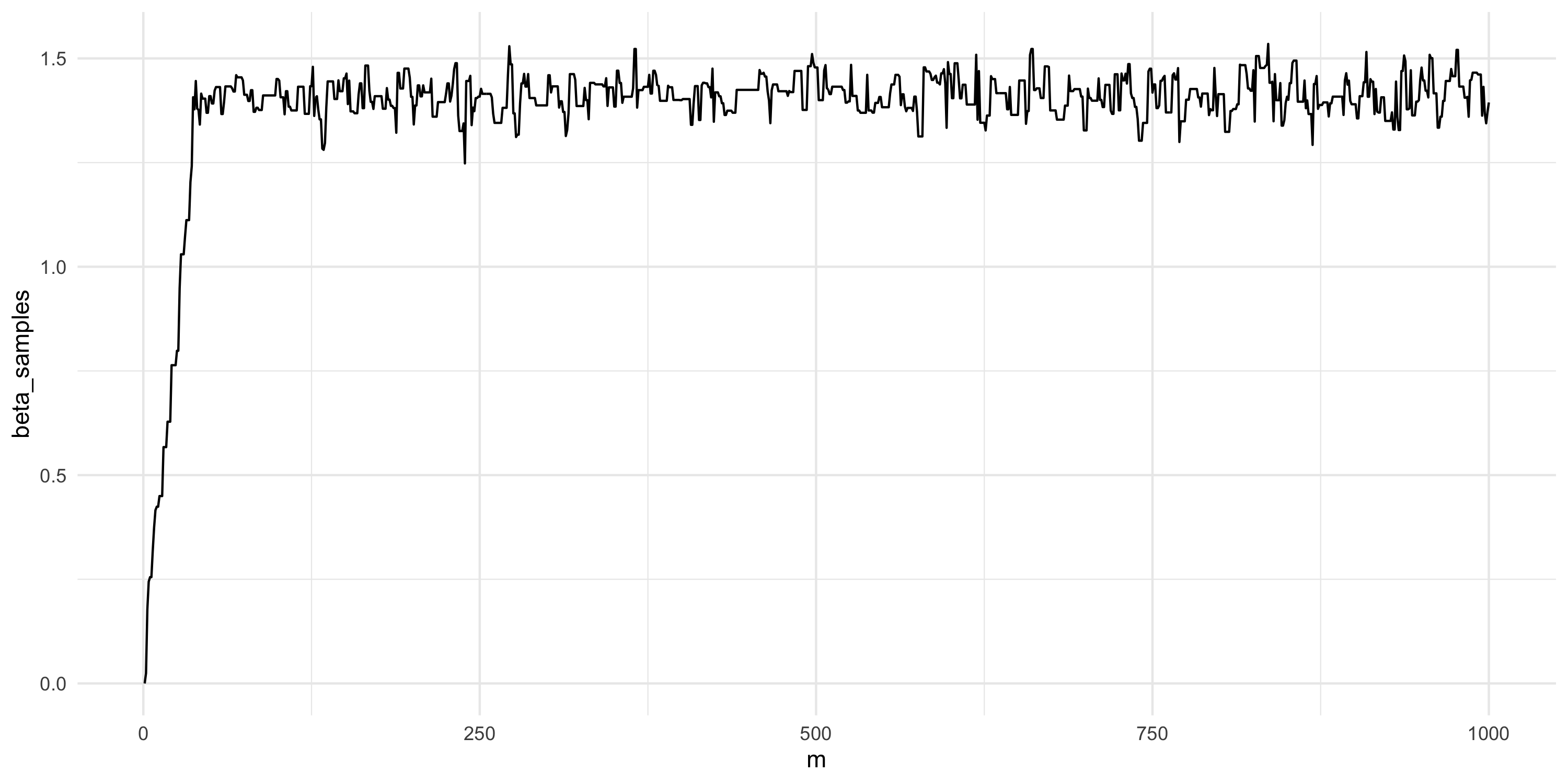
Setting up Metropolis algorithms
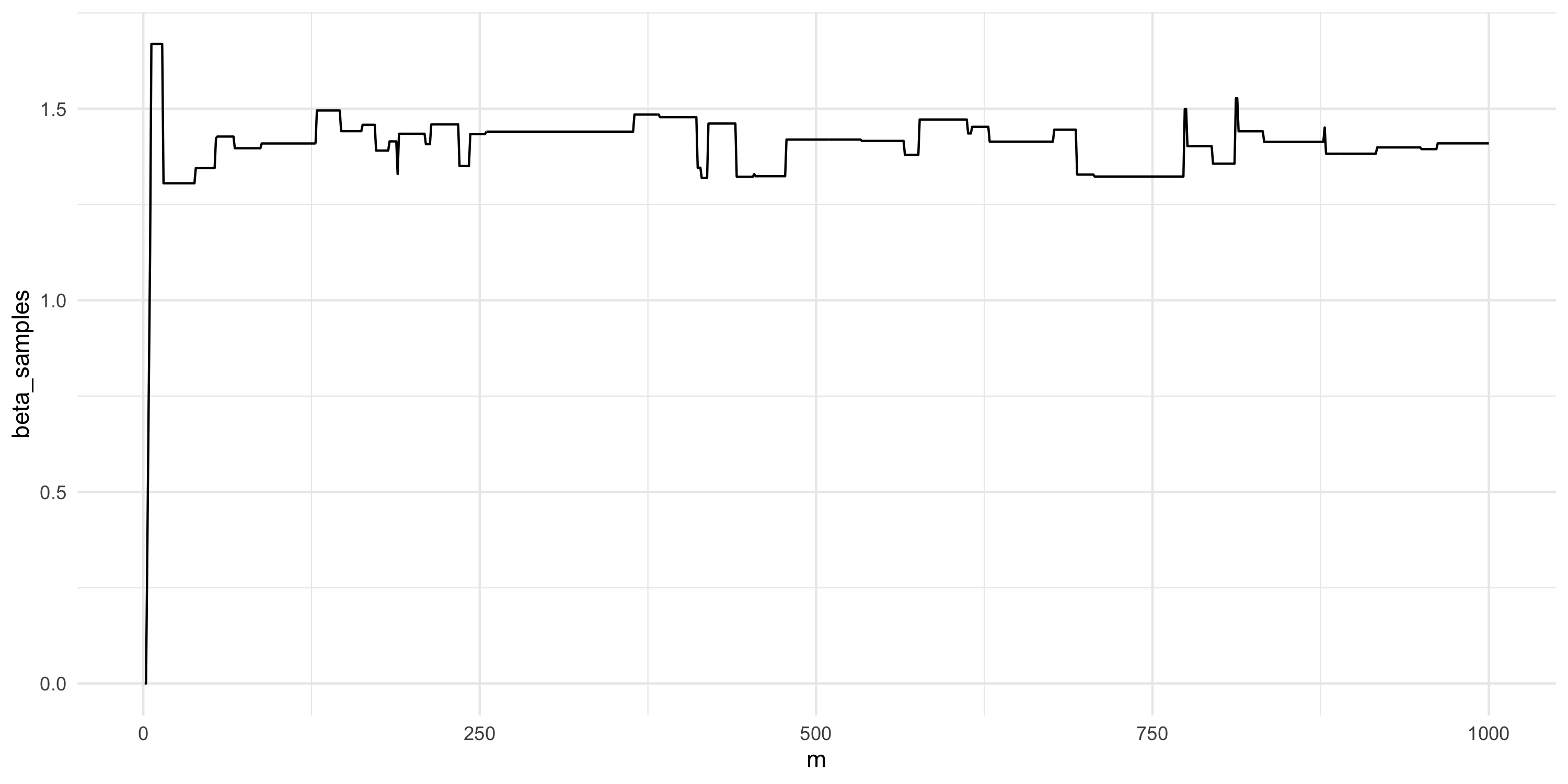
- Let’s run this chain for much longer
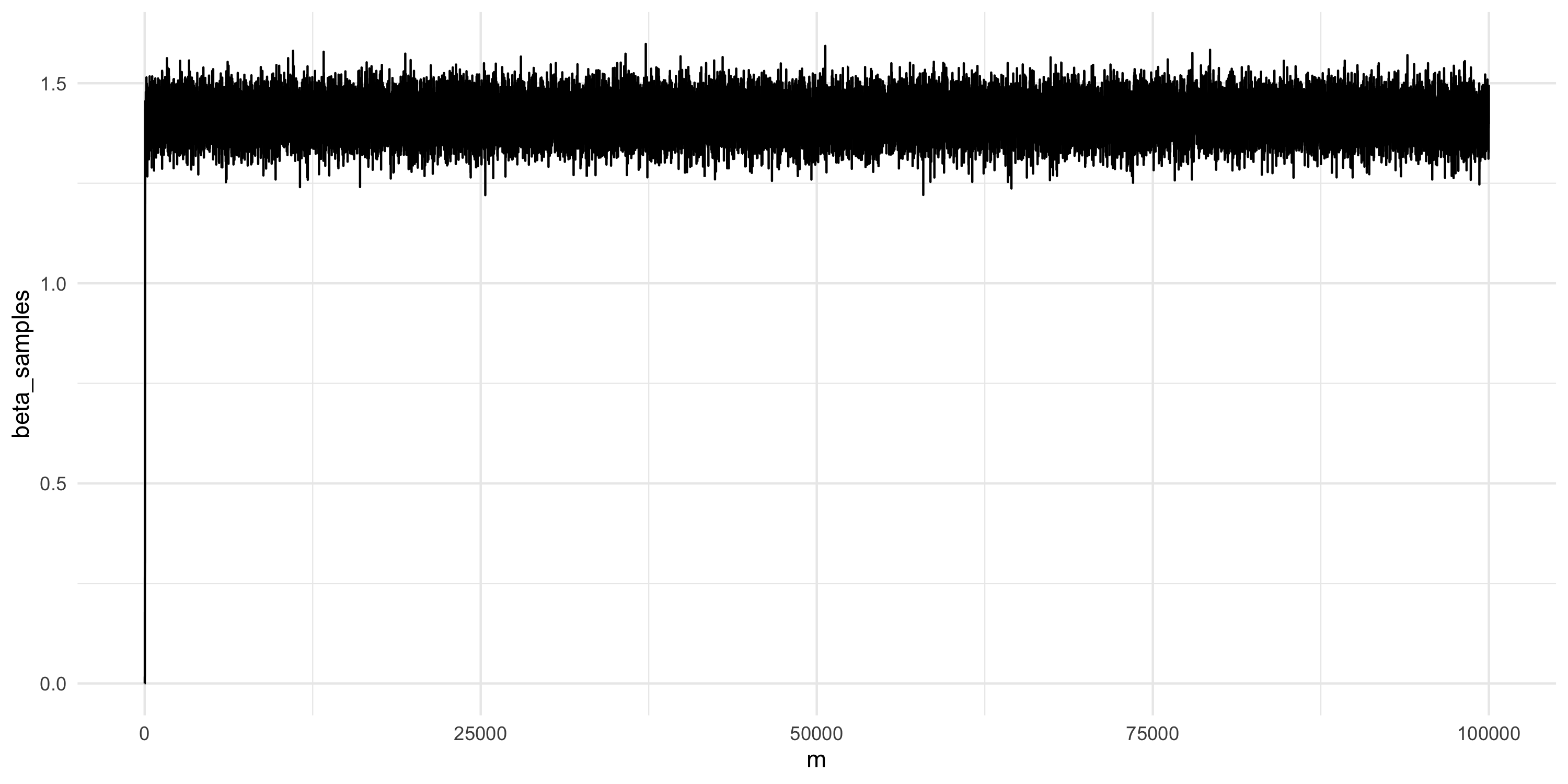
Setting up Metropolis algorithms
- Drop initial samples as they are burn-in
- Then learn about the posterior by taking summaries
- Example: estimate density using MCMC samples
- Compare with our previous approximation of the posterior (in magenta)
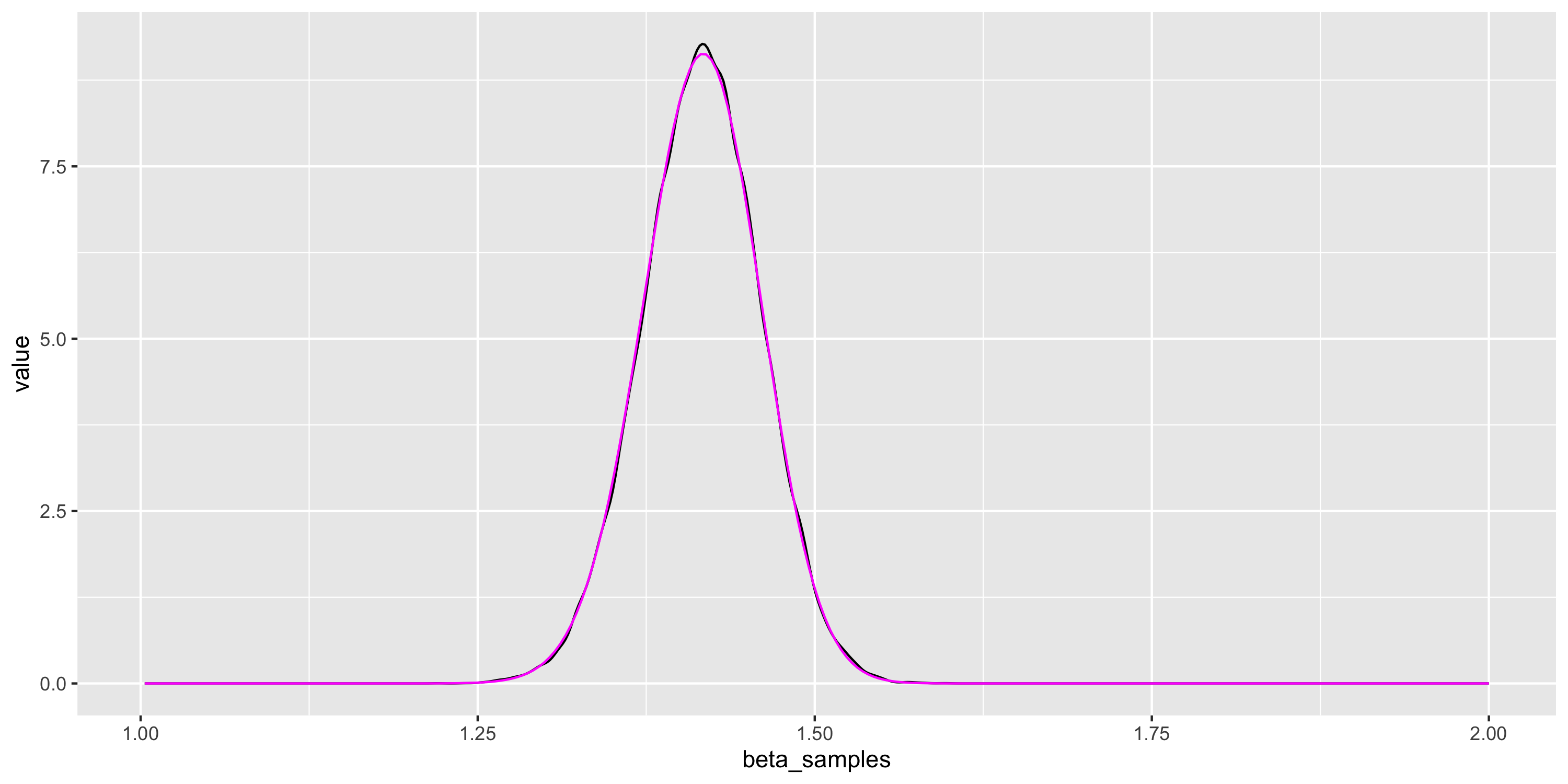
More difficult
- Now, same problem but the number of predictors is 2 and we make them correlated
- This induces posterior correlation on their regression coefficients
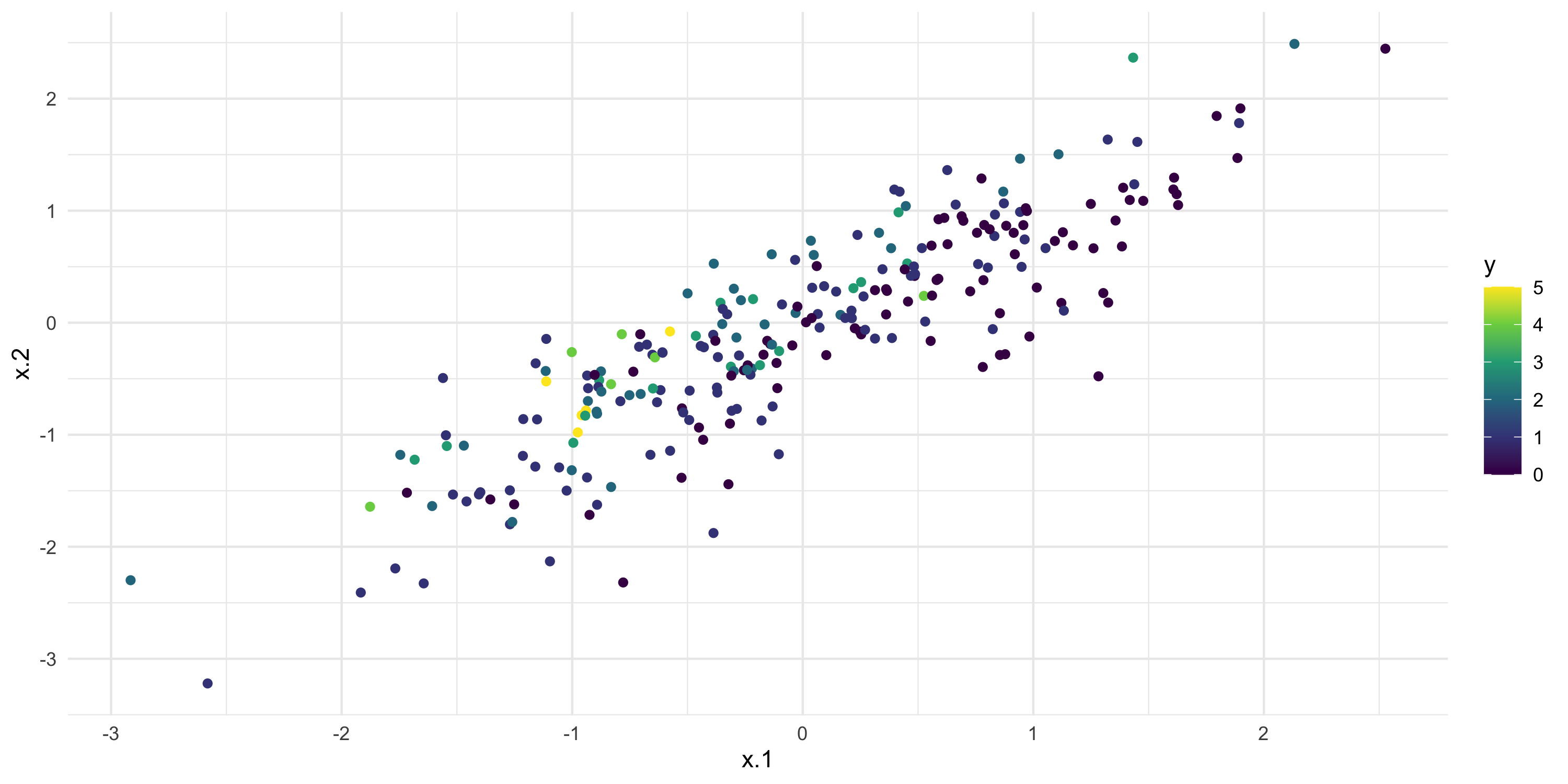
Numerical approximation of the 2D posterior
- We do the same thing as before, but now we work in 2 dimensions
- We let \beta \sim N(0, I_2) be our prior
beta_vals <- expand.grid(b1vals <- seq(-2, 0, length.out=500),
b2vals <- seq(0, 2, length.out=500))
colnames(beta_vals) <- c("beta.1", "beta.2")
delta <- diff(b1vals)[1]^2
post_vals_unnorm <- beta_vals %>% apply(1, \(beta) exp(sum(dpois(y, exp(X %*% beta), log=TRUE)) + sum(dnorm(beta, log=TRUE))))
post_vals <- post_vals_unnorm/sum(post_vals_unnorm)/delta
df_post <- data.frame(beta_vals, post=post_vals)
ggplot(df_post, aes(x=beta.1, y=beta.2, fill=post)) +
labs(fill="Posterior") +
geom_raster() +
scale_fill_scico(palette="davos", direction=-1) +
theme_minimal()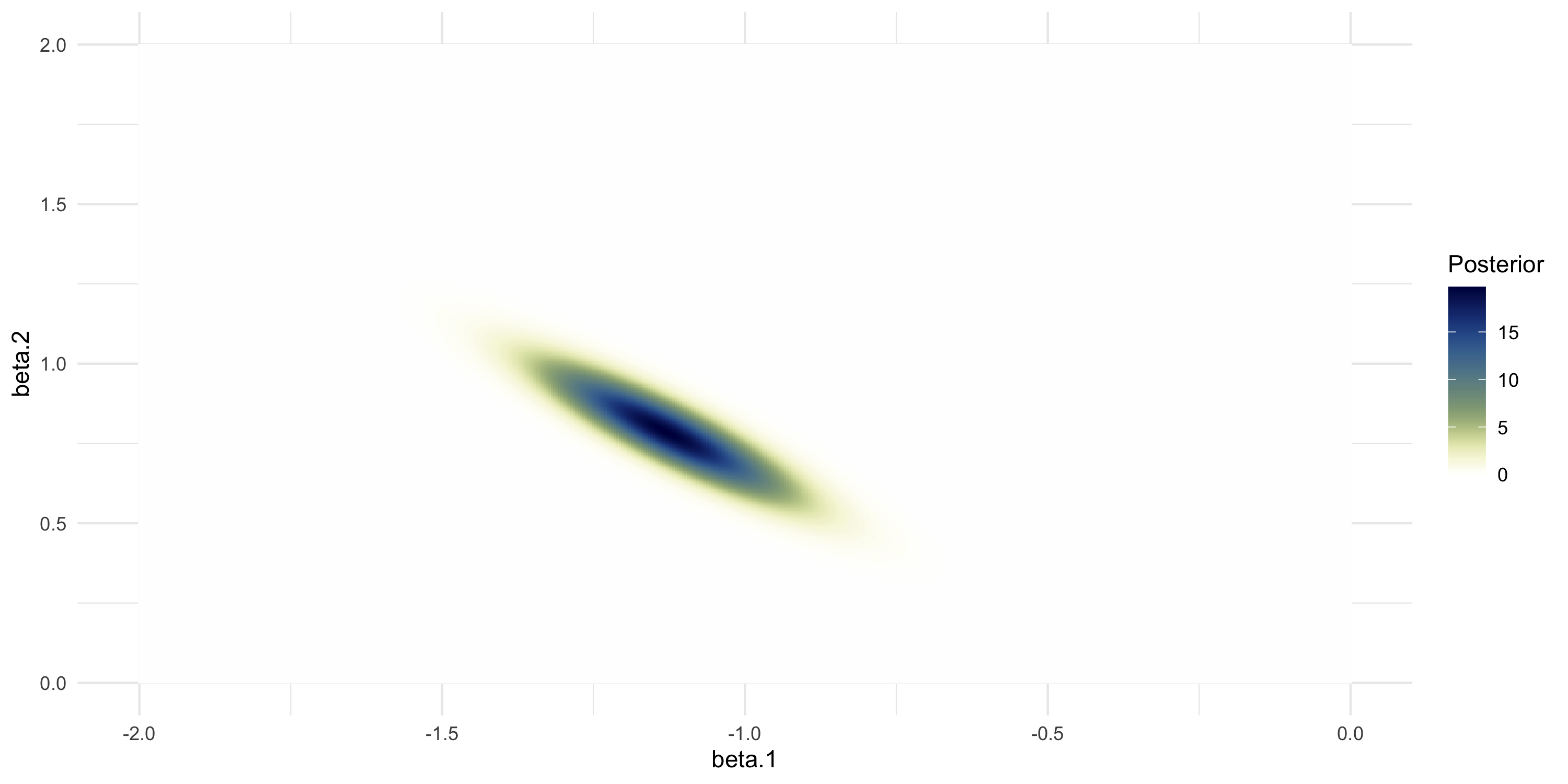
Setting up random walk Metropolis
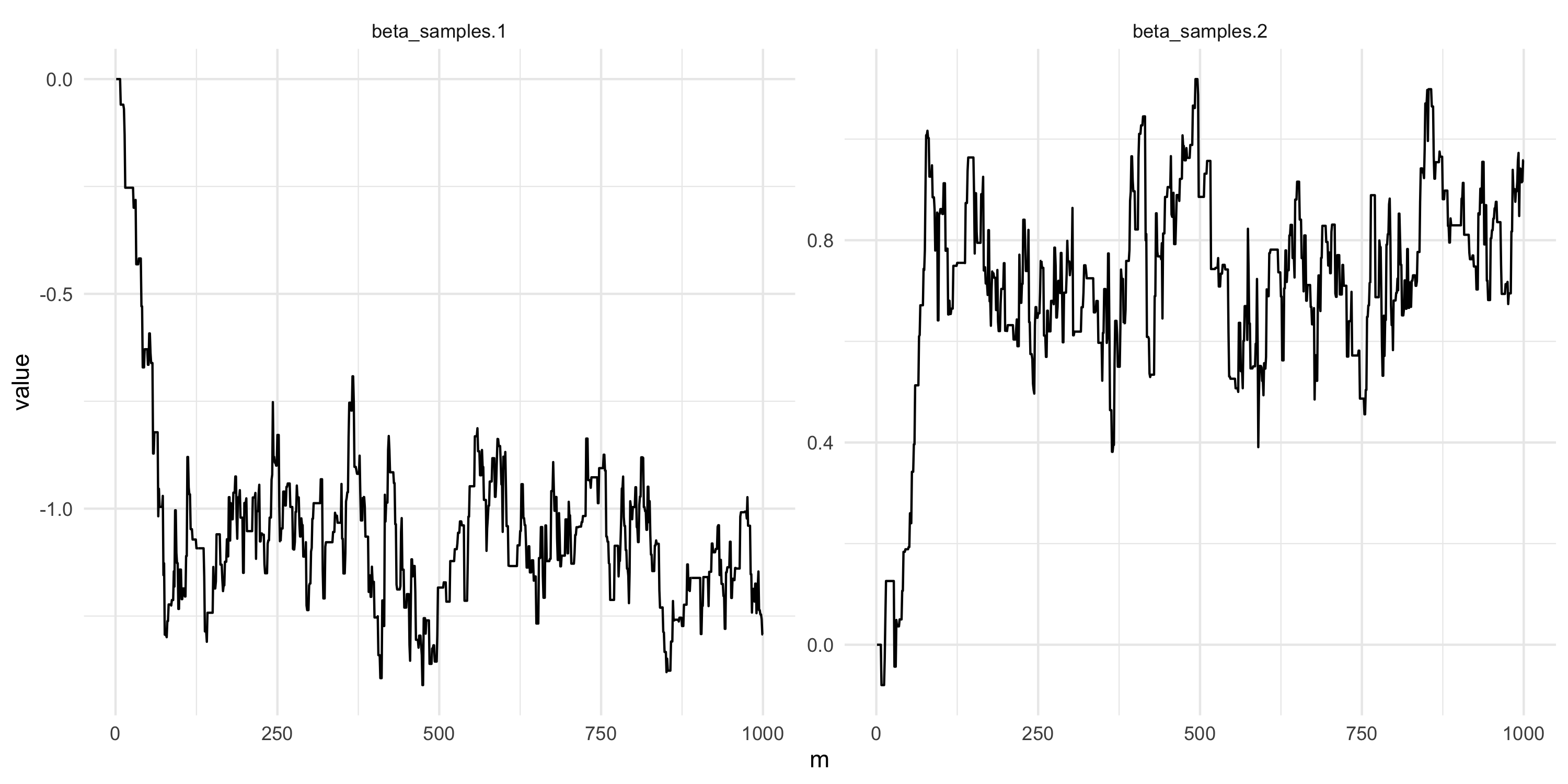
Setting up random walk Metropolis
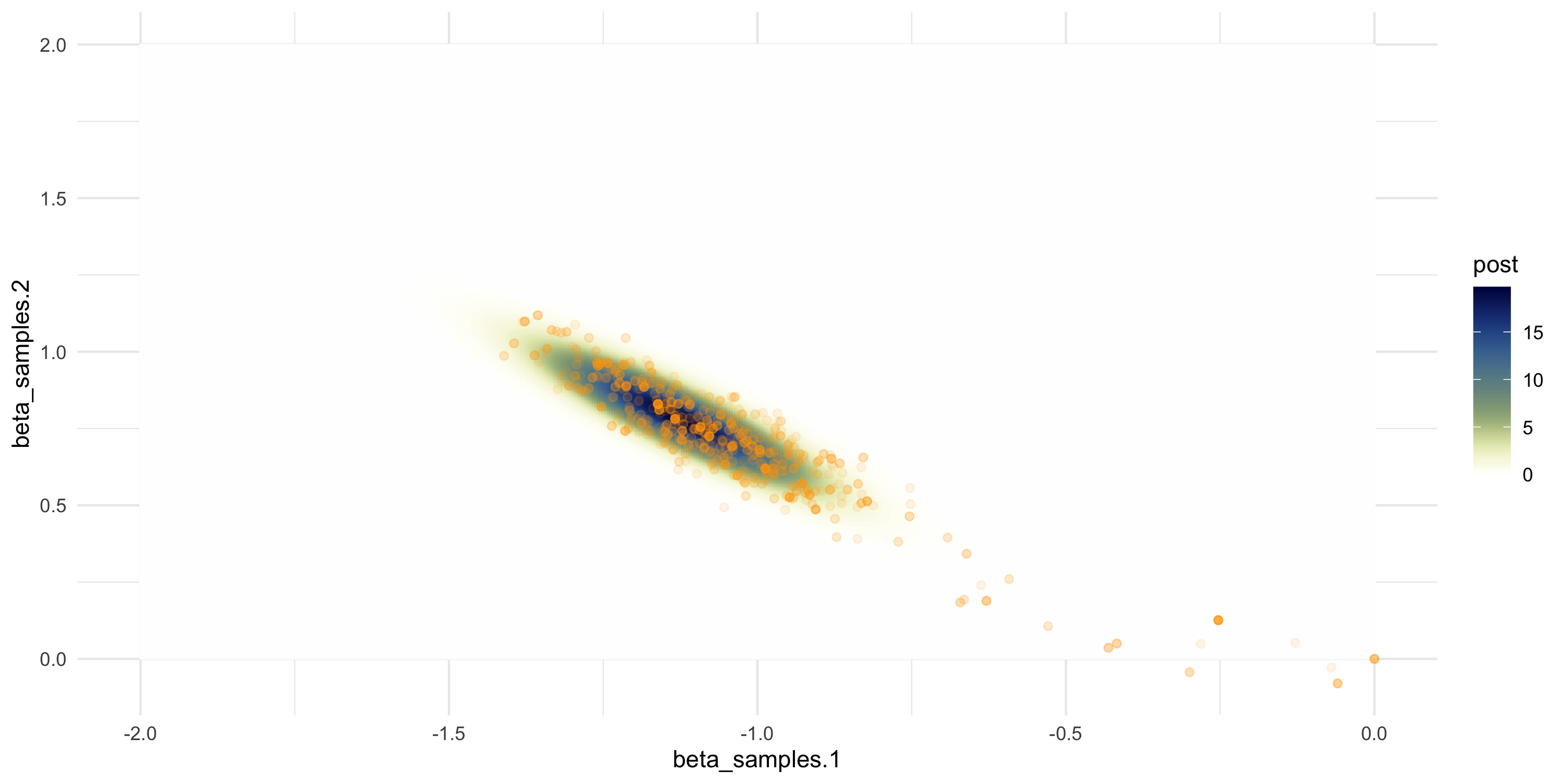
Adaptive Metropolis algorithms
- Tuning the proposal so it behaves nicely can be tedious
- This can be made automatic via adaptive Metropolis algorithms
- I am providing you with source code to run adaptive Metropolis
- This is a modification of
adaptMCMC::MCMC. Runs Robust Adaptive Metropolis, Vihola (2012) - Includes Jacobian adjustment
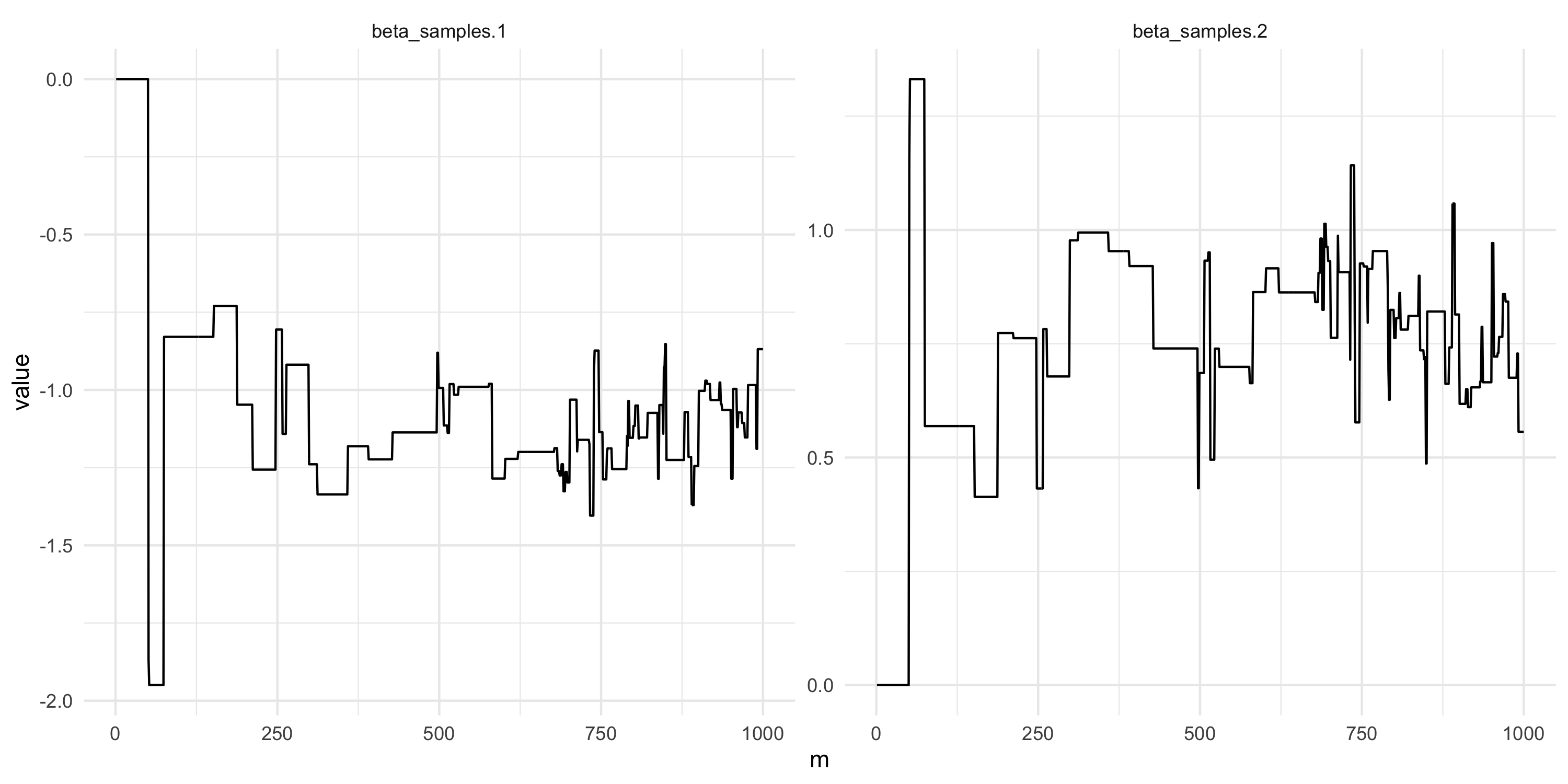
Adaptive Metropolis algorithms
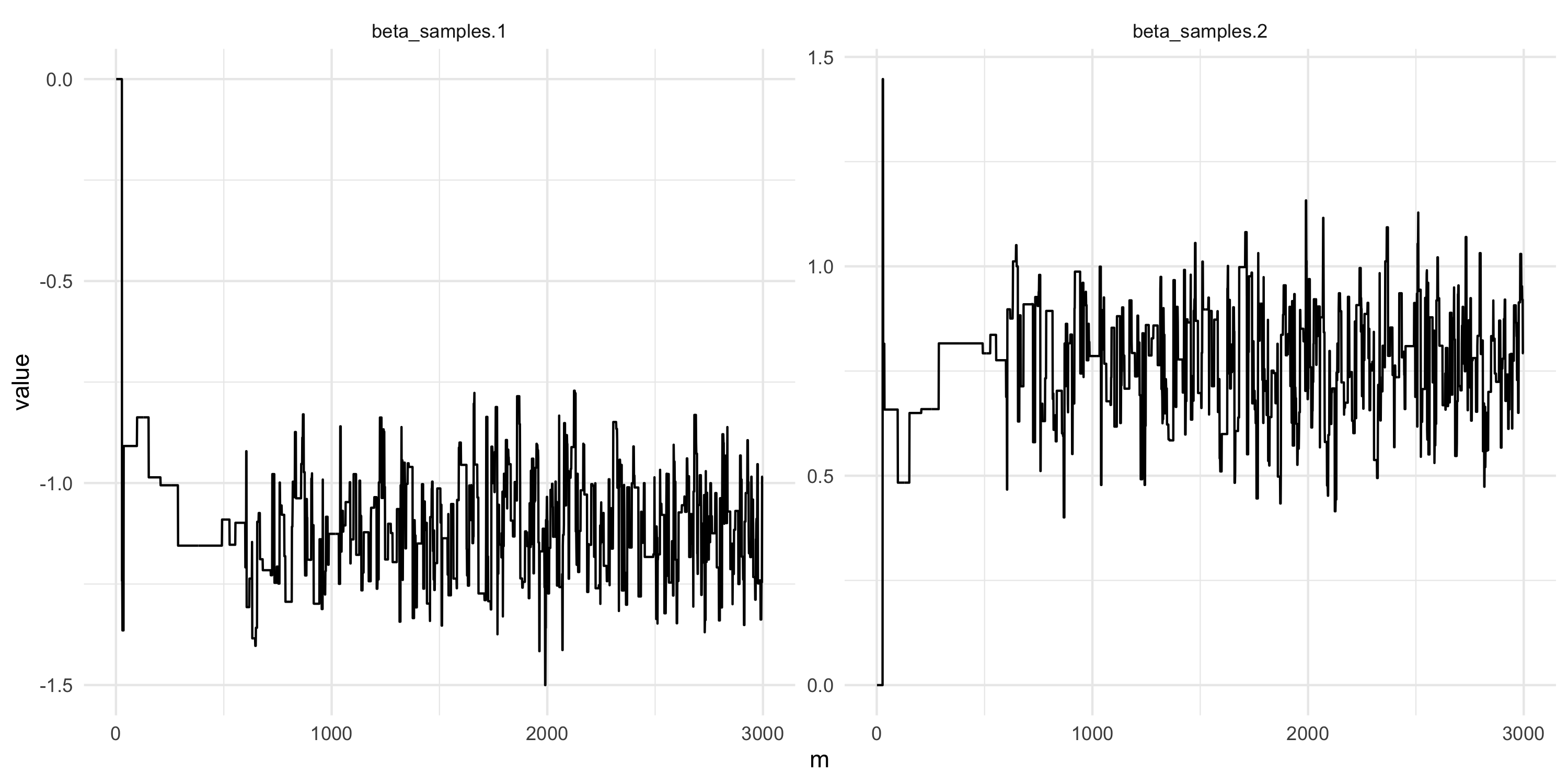
Analyzing MCMC output
- We can use package
codafor MCMC convergence analysis and other MCMC tools - Convergence analysis is based on output from multiple runs of MCMC
library(coda)
n_iter <- 1000
run_1 <- MCMCmod(mypost, n_iter, c(0, 0), cbind(c(-10,-10), c(10,10)), acc.rate = 0.25)$samples %>% as.mcmc()
run_2 <- MCMCmod(mypost, n_iter, c(0, 0), cbind(c(-10,-10), c(10,10)), acc.rate = 0.25)$samples %>% as.mcmc()
(analyse_converg <- gelman.diag(list(run_1, run_2)))Potential scale reduction factors:
Point est. Upper C.I.
[1,] 1.25 1.82
[2,] 1.07 1.28
Multivariate psrf
1.21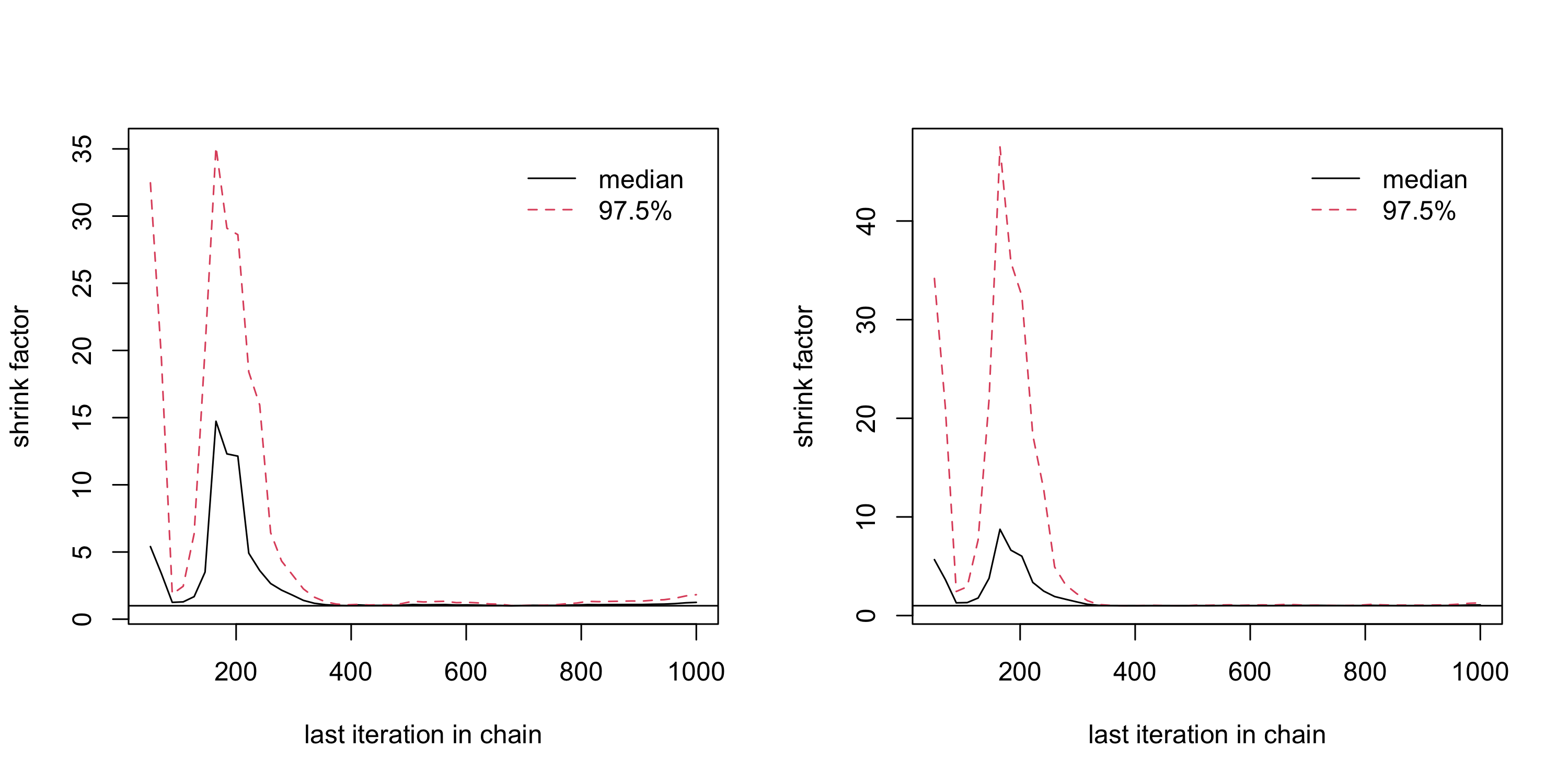
Analyzing MCMC output
- We can use package
codafor MCMC convergence analysis and other MCMC tools - Convergence analysis is based on output from multiple runs of MCMC
n_iter <- 20000
run_1 <- MCMCmod(mypost, n_iter, c(0, 0), cbind(c(-10,-10), c(10,10)), acc.rate = 0.25)$samples %>%
head(-n_iter/2) %>% as.mcmc()
run_2 <- MCMCmod(mypost, n_iter, c(0, 0), cbind(c(-10,-10), c(10,10)), acc.rate = 0.25)$samples %>%
head(-n_iter/2) %>% as.mcmc()
(analyse_converg <- gelman.diag(list(run_1, run_2)))Potential scale reduction factors:
Point est. Upper C.I.
[1,] 1.00 1.02
[2,] 1.01 1.02
Multivariate psrf
1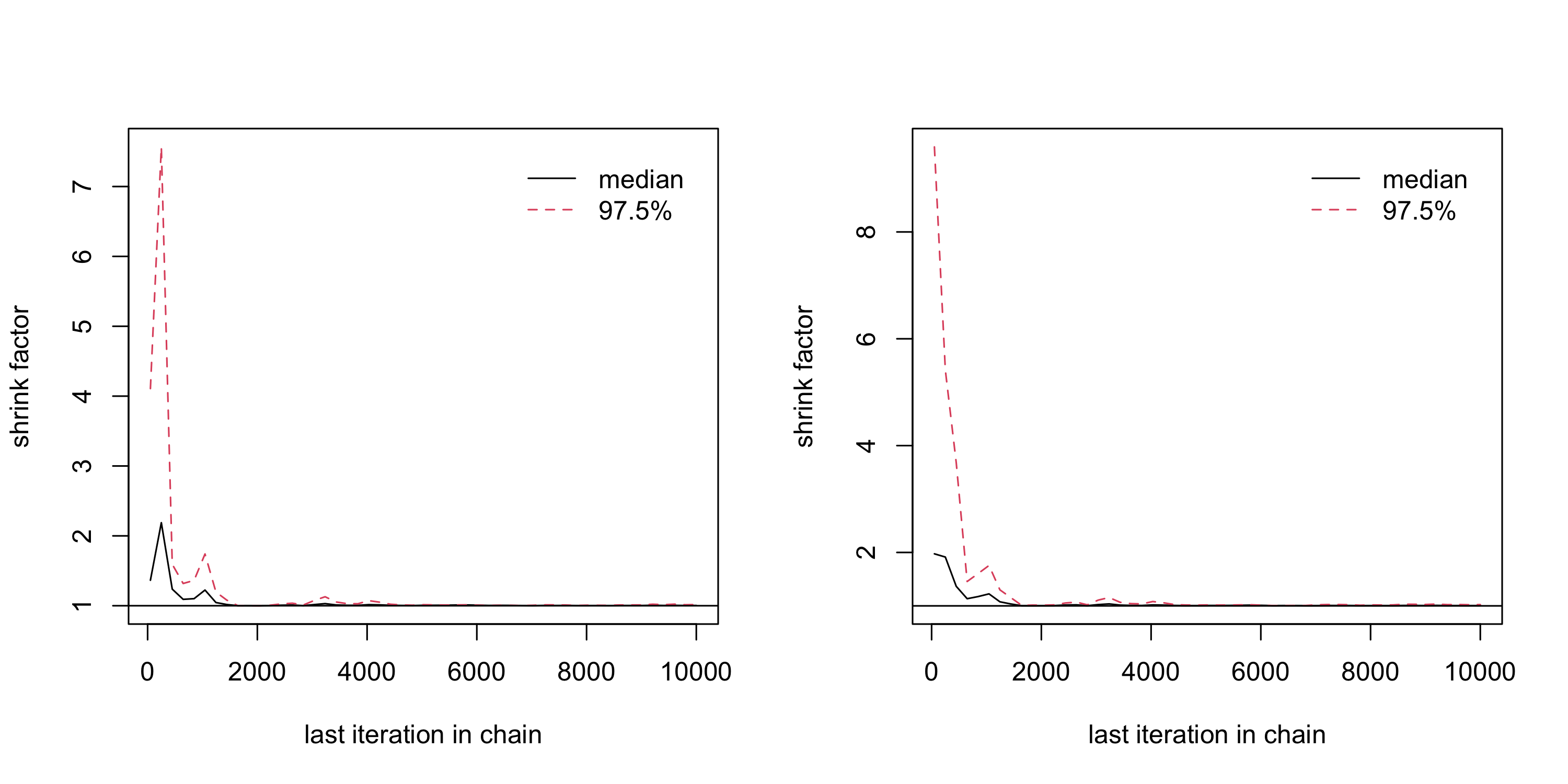
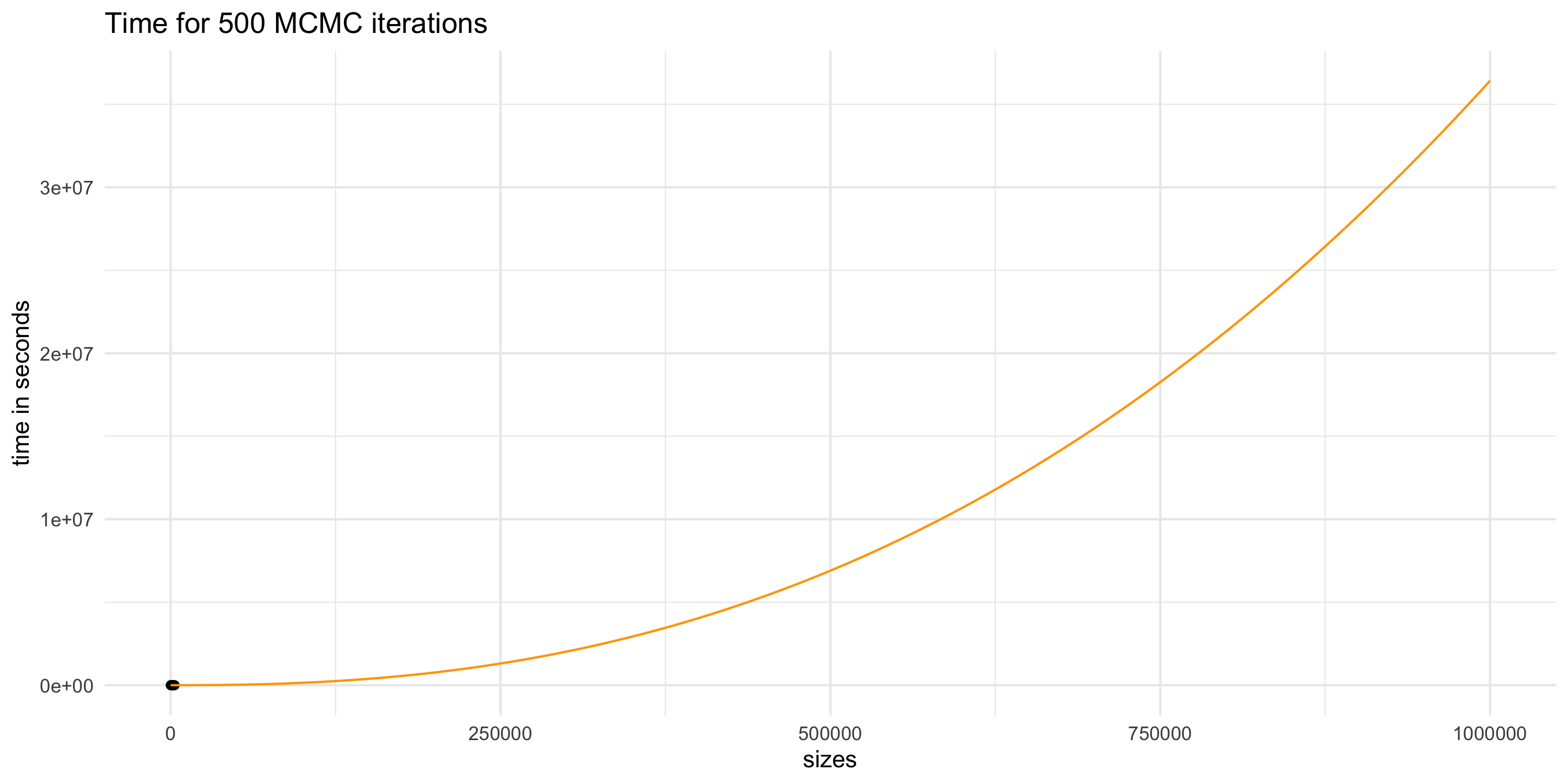
Projecting compute time for GP models
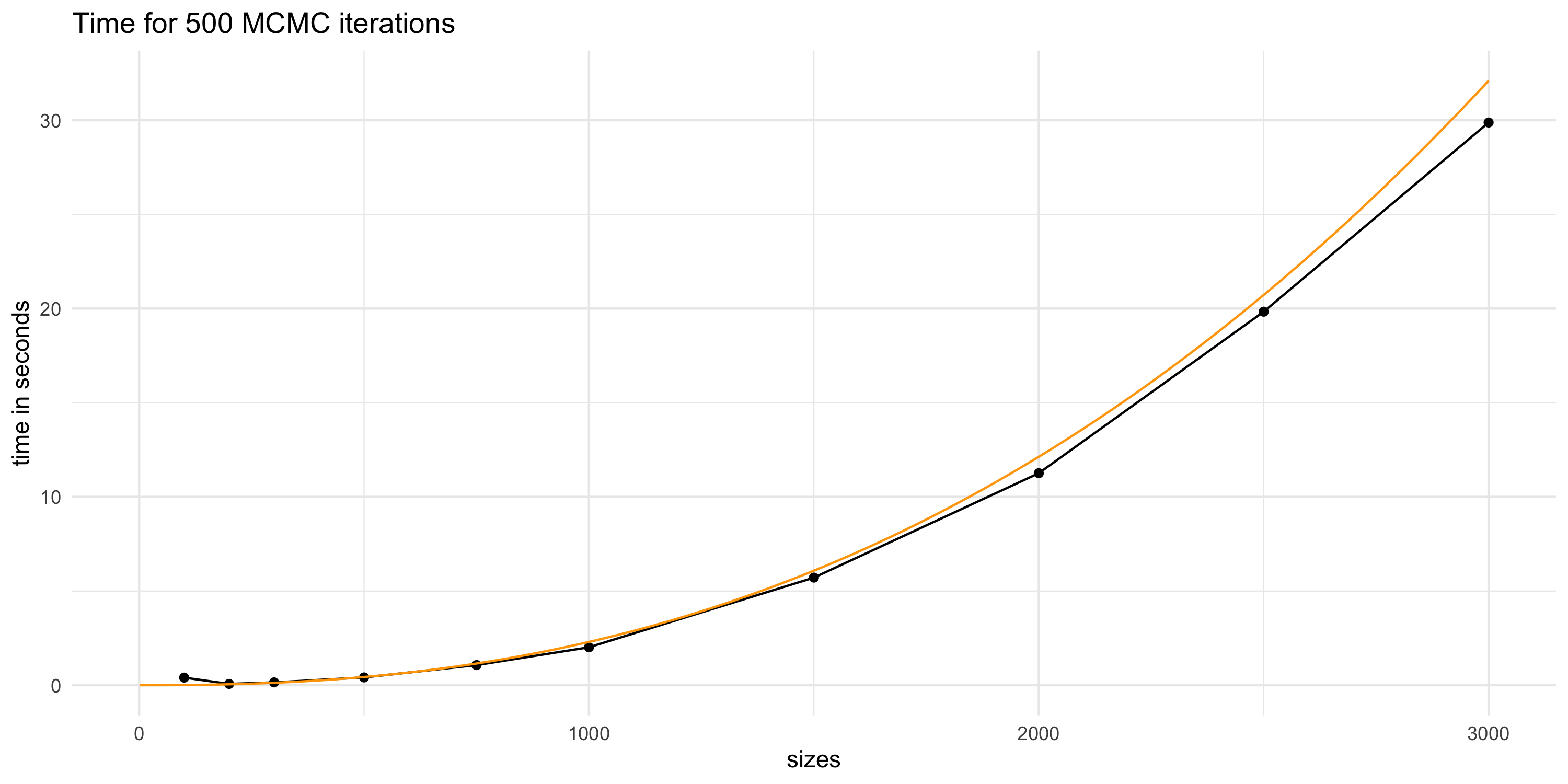
Projecting compute time for GP models