Gaussian Processes models for point-referenced spatial data, part 2
Spatial Statistics - BIOSTAT 696/896
Michele Peruzzi
University of Michigan
Likelihood inference: MLE estimation of covariance parameters
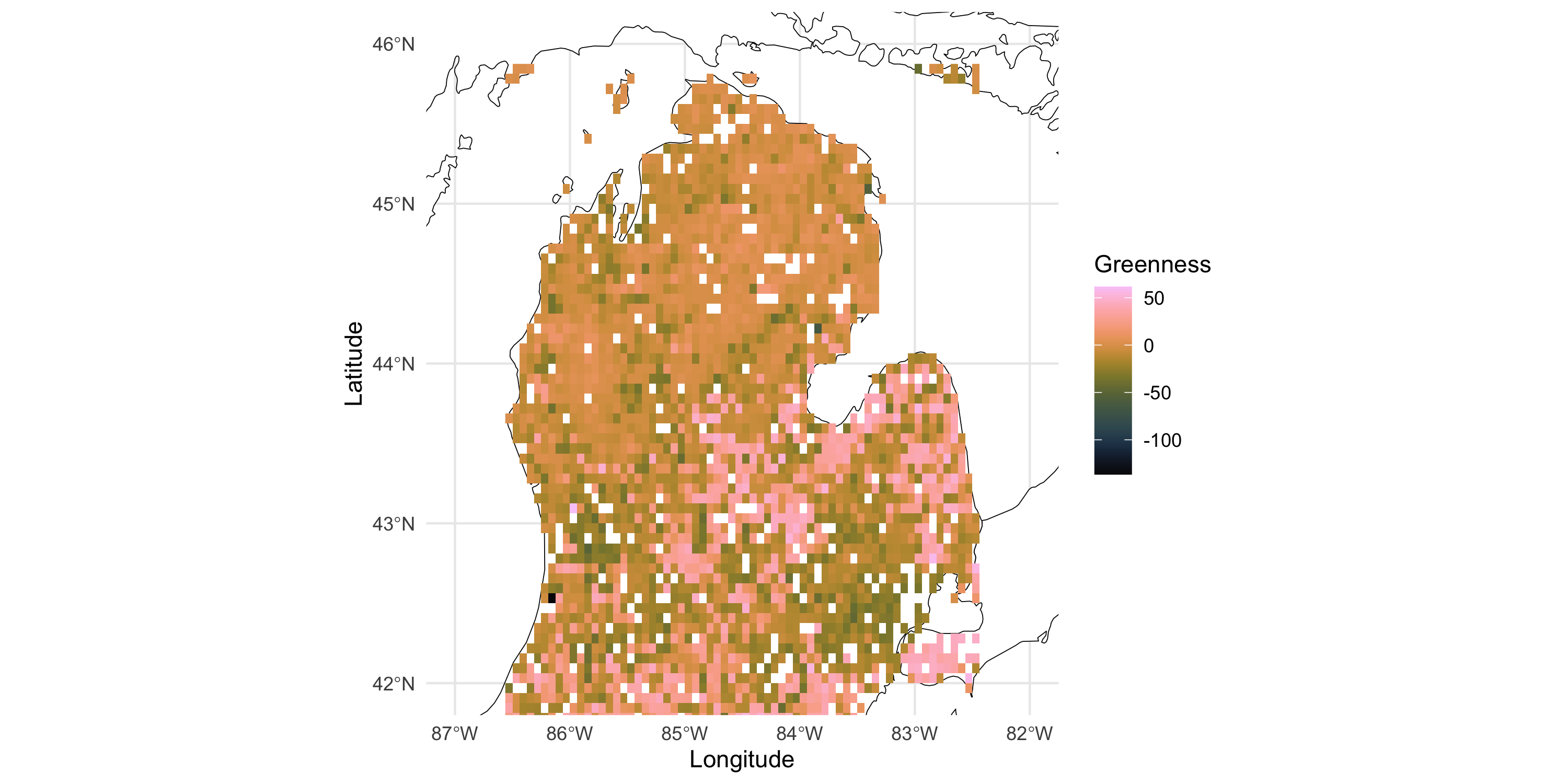
Let’s consider the Greenness data
Small preprocessing: remove sample mean
Likelihood inference: MLE estimation of covariance parameters
Call \cal T our set of observed locations. The data vector at \cal T is Y_{\cal T}, or simply Y
Let’s use an exponential covariance model for a mean-zero GP
Because we are directly assuming that the data are a realization of a GP, this is called a GP model of the response or response model Y(\cdot) \sim GP(0, C_{\theta}(\cdot)) For our n-dimensional vector of observations, we have Y \sim N(0, C_{\theta}) where the (i,j) element of the C_{\theta} matrix is C_{\theta}(i,j) = \sigma^2 \exp \{ -\phi \|s_i - s_j \| \} where s_i, s_j \in \cal T.
Likelihood inference: MLE estimation of covariance parameters
Recall from preliminaries that because of your MVN assumption, we can write
\Phi^{-1} is the inverse CDF of the (univariate) Gaussian. In R, qnorm.
Because \cal U can be large, applying the above formula for each element of \cal U saves on memory relative to extracting the diagonal elements from C_{\cal U | \cal T}, but that would also work
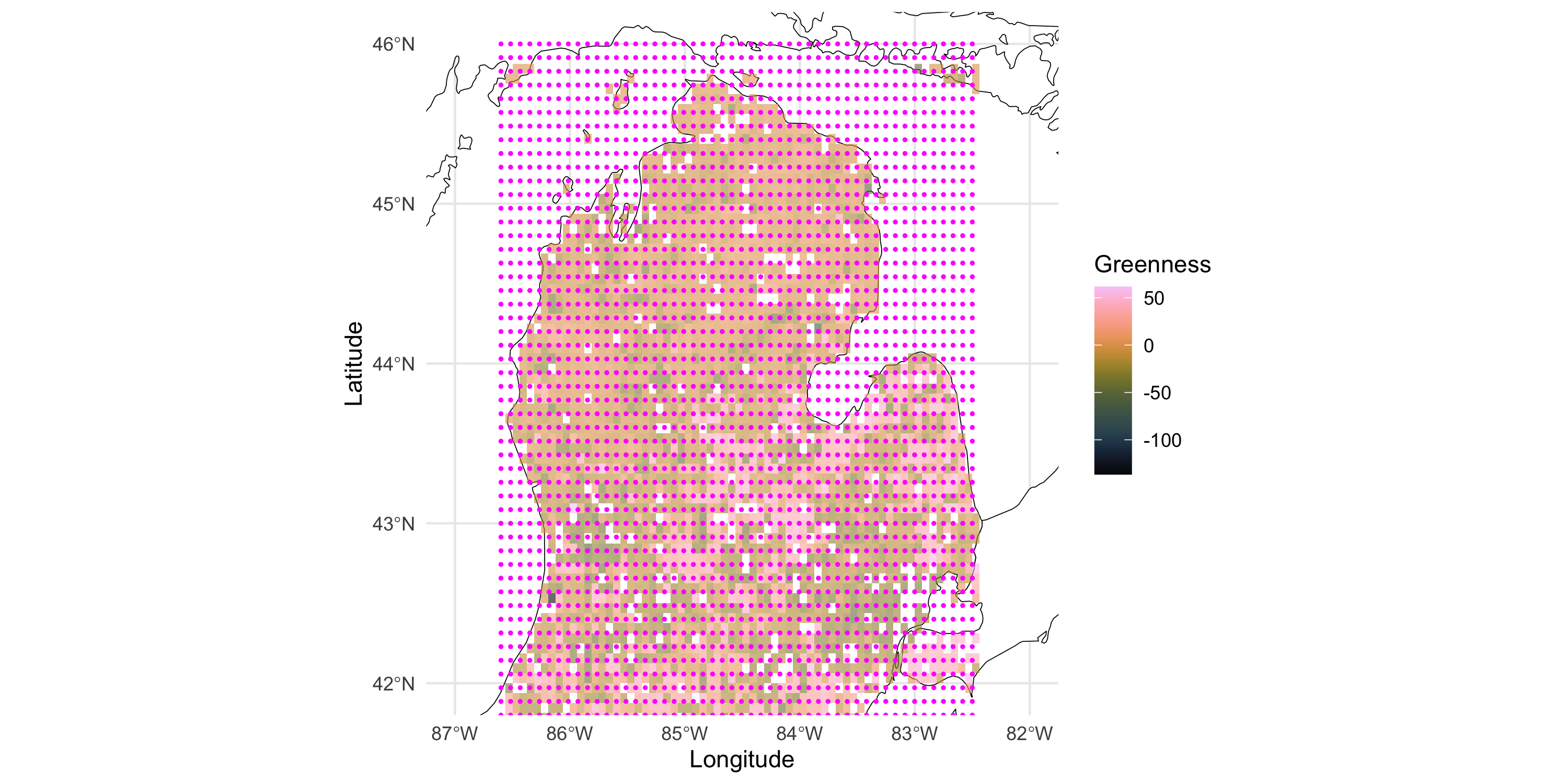
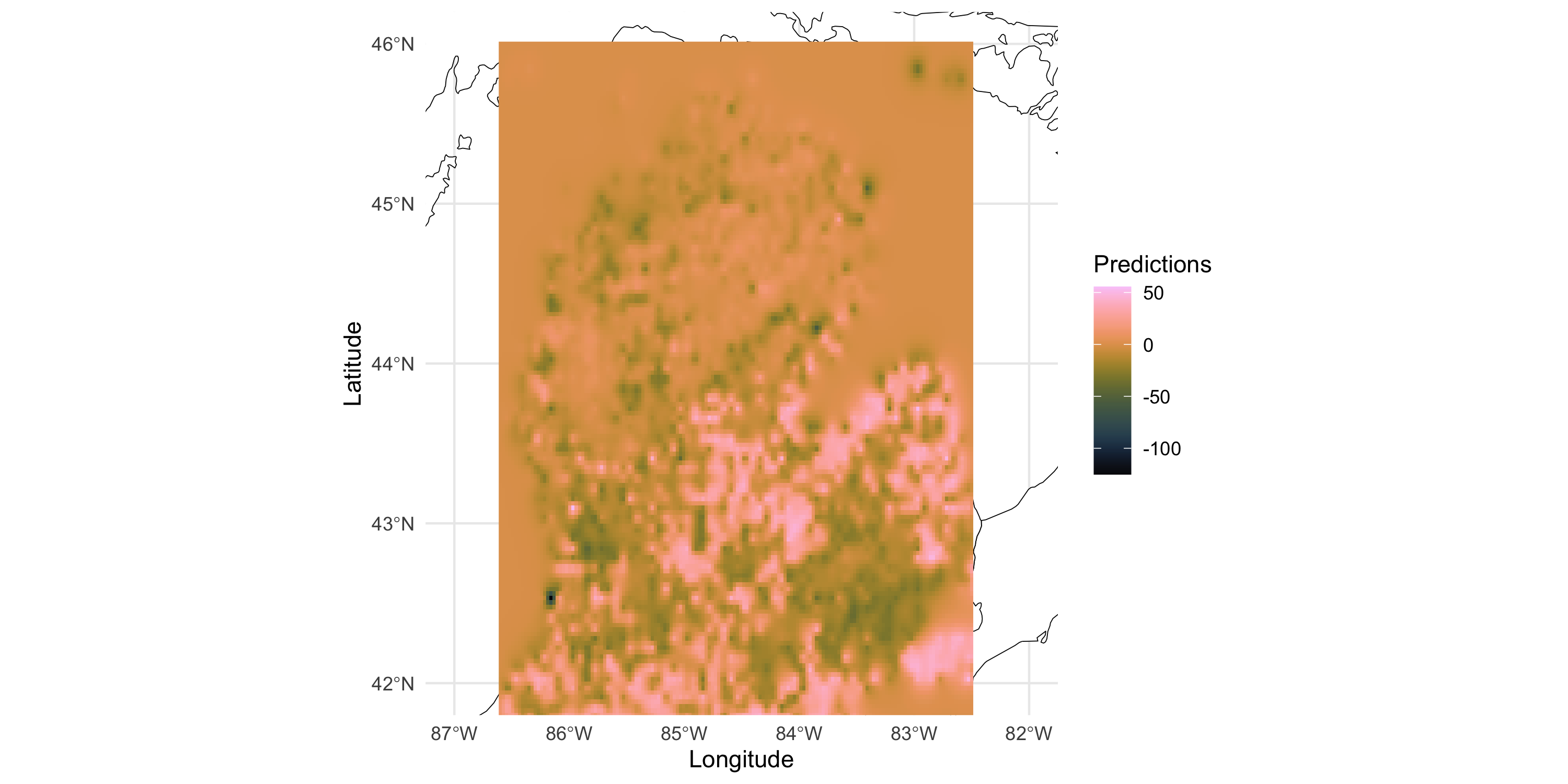
Making predictions based on a GP response model
Making predictions based on a GP response model
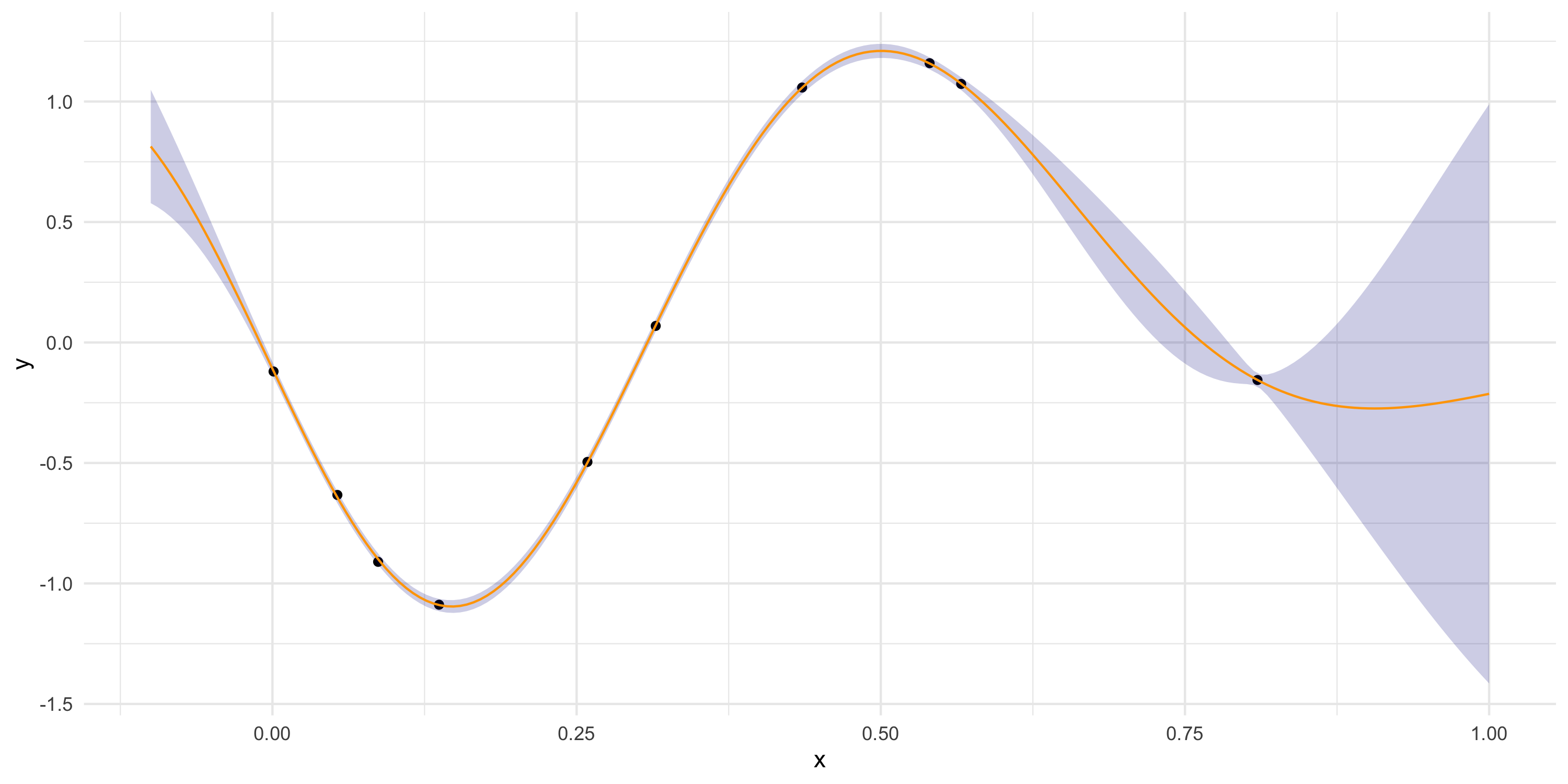
As we move away from the observed data
The predictive mean gets closer to 0 (which is the prior mean we have assumed for the GP)
Uncertainty bands become wider
This matches the intuition that spatial dependence is determined by distance
More on point predictions and uncertainty bands
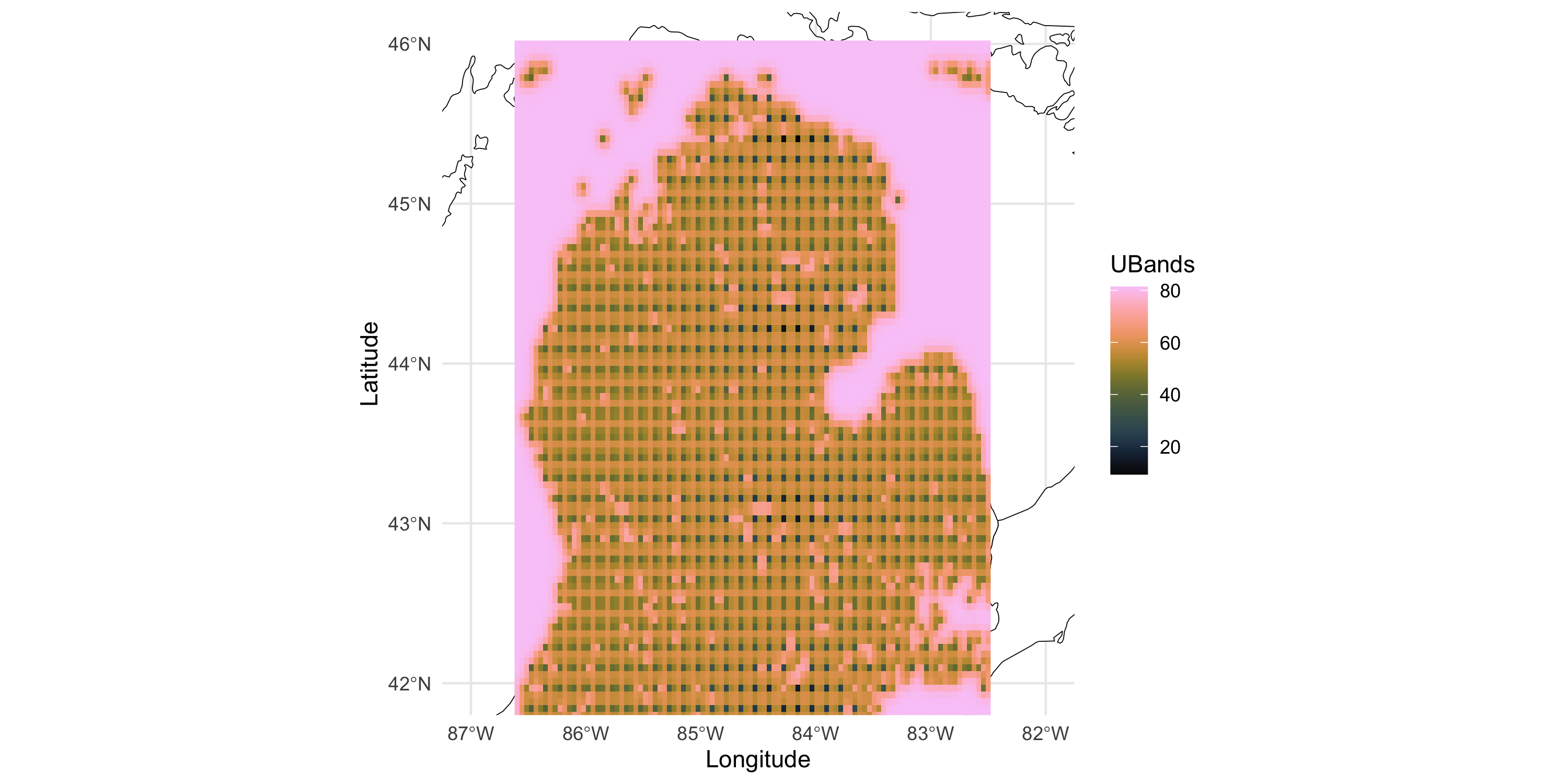
We considered the Greenness dataset which is a gridded dataset in 2 dimensions
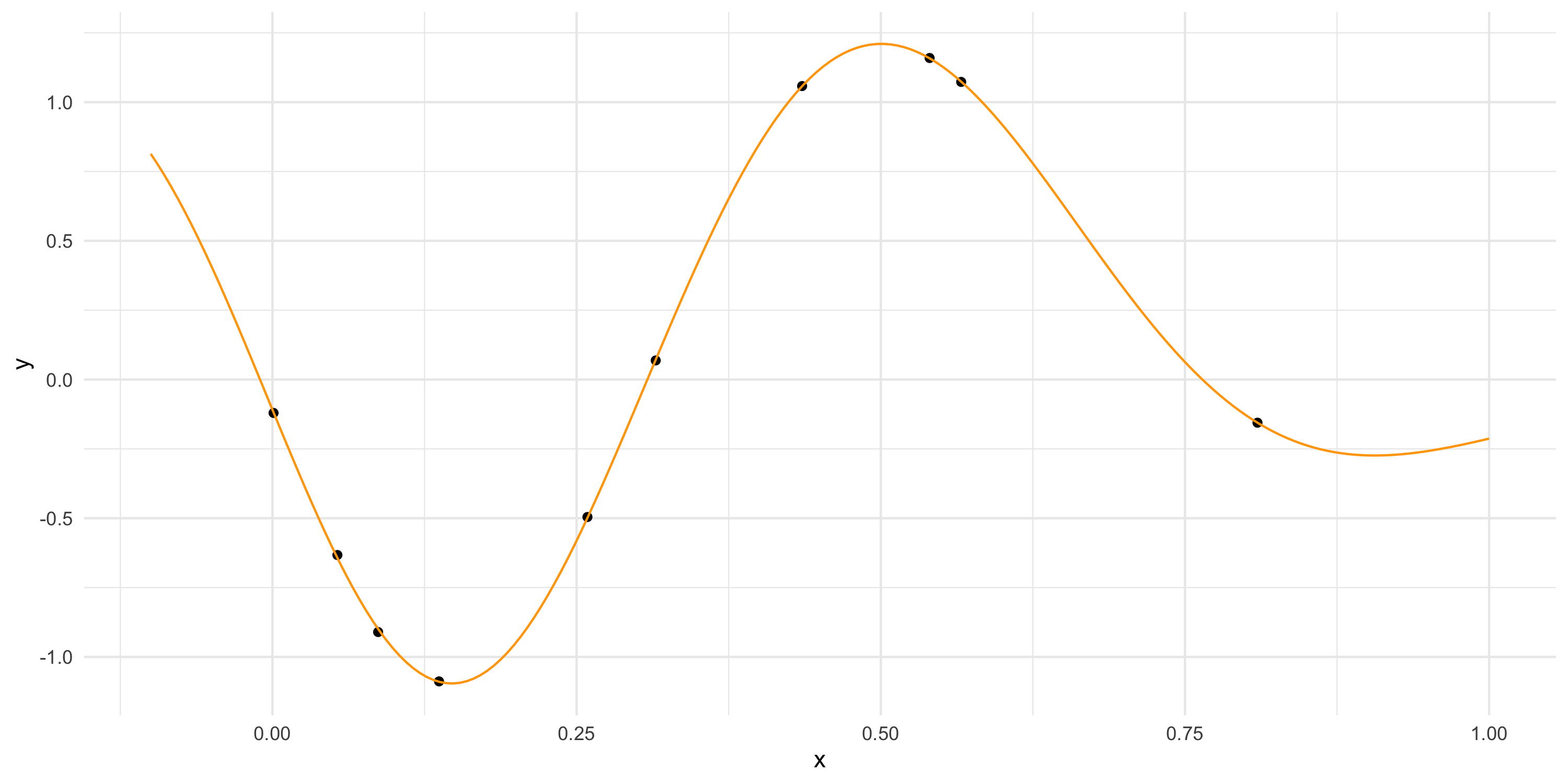
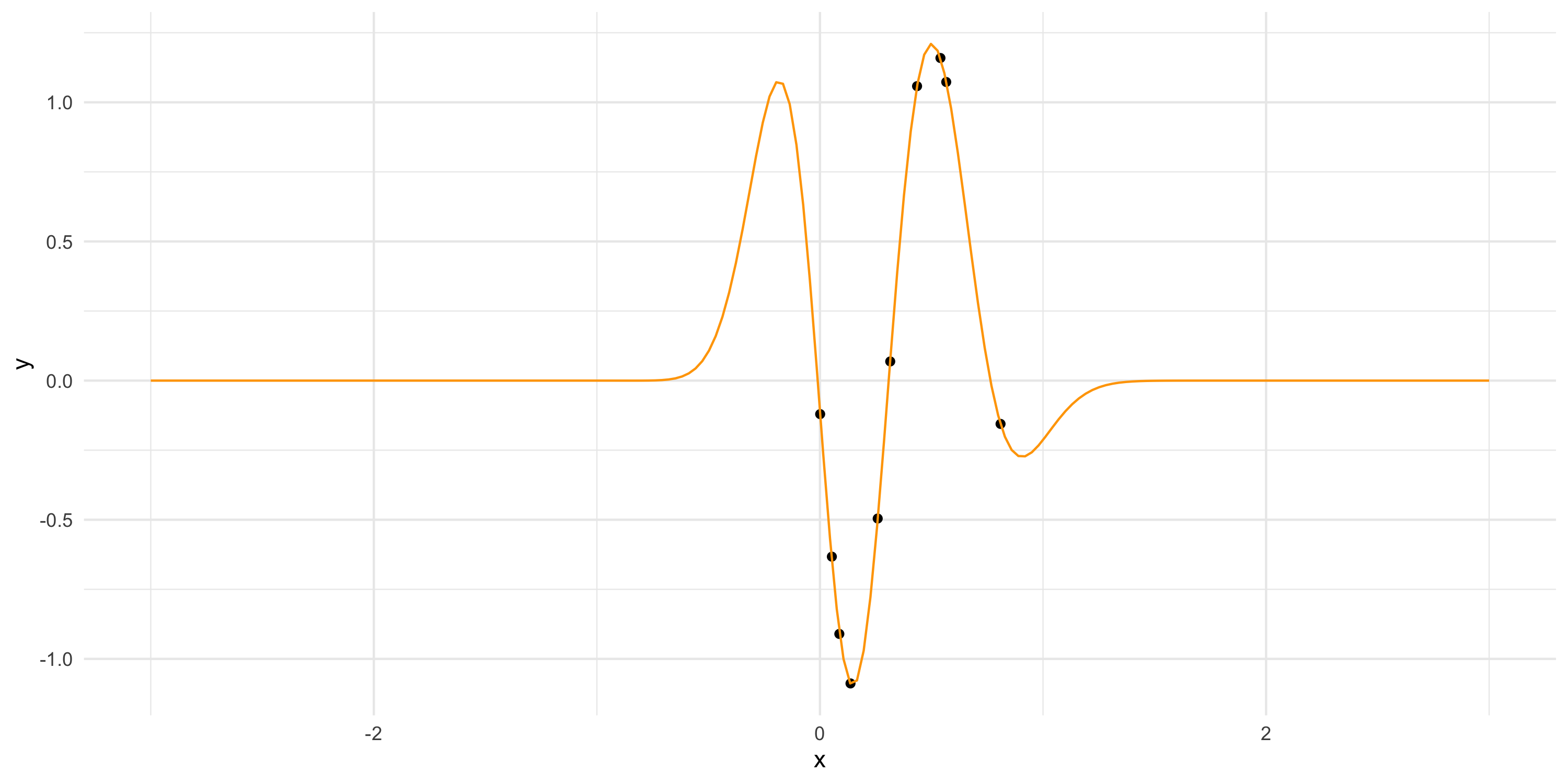
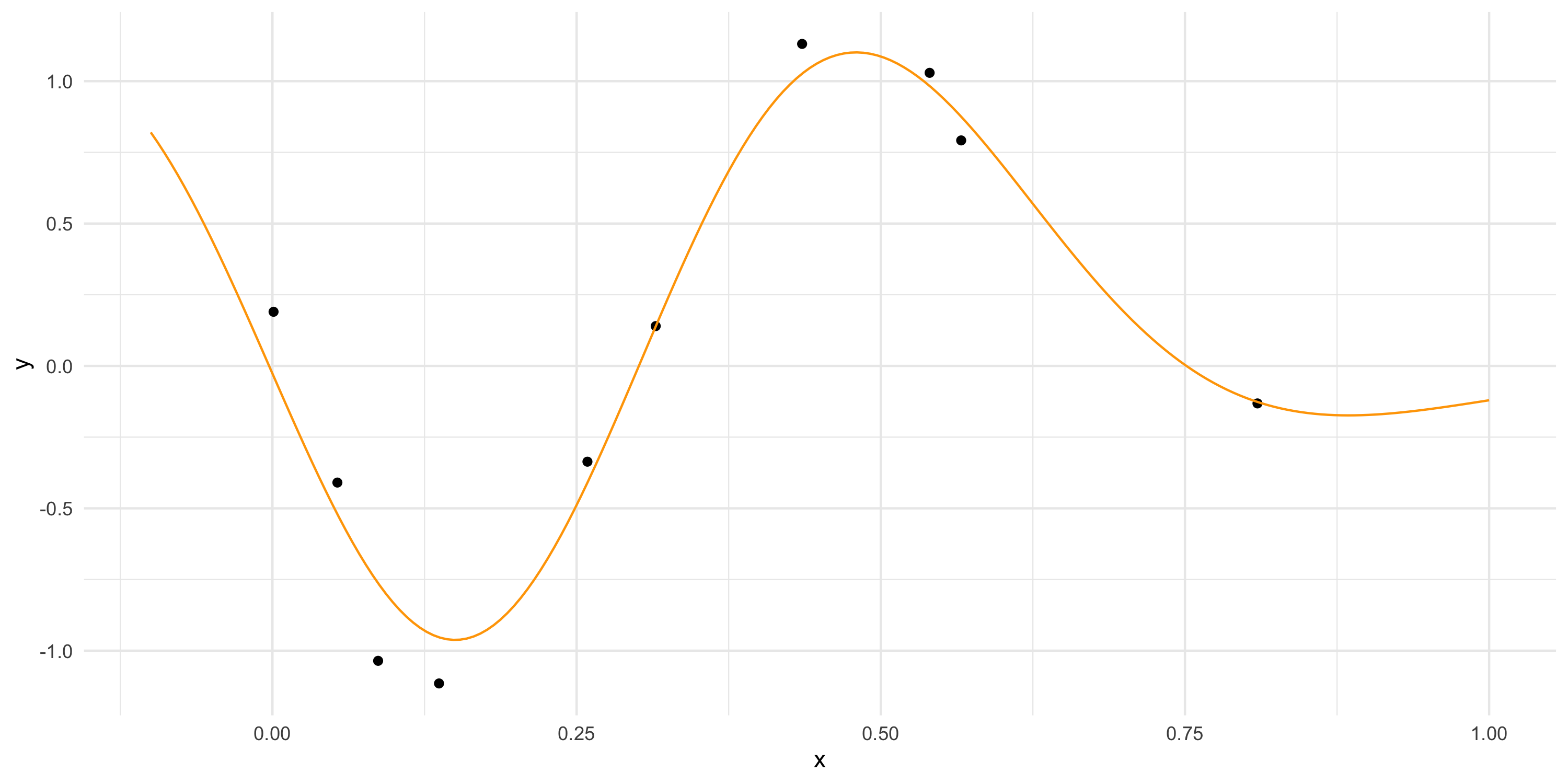
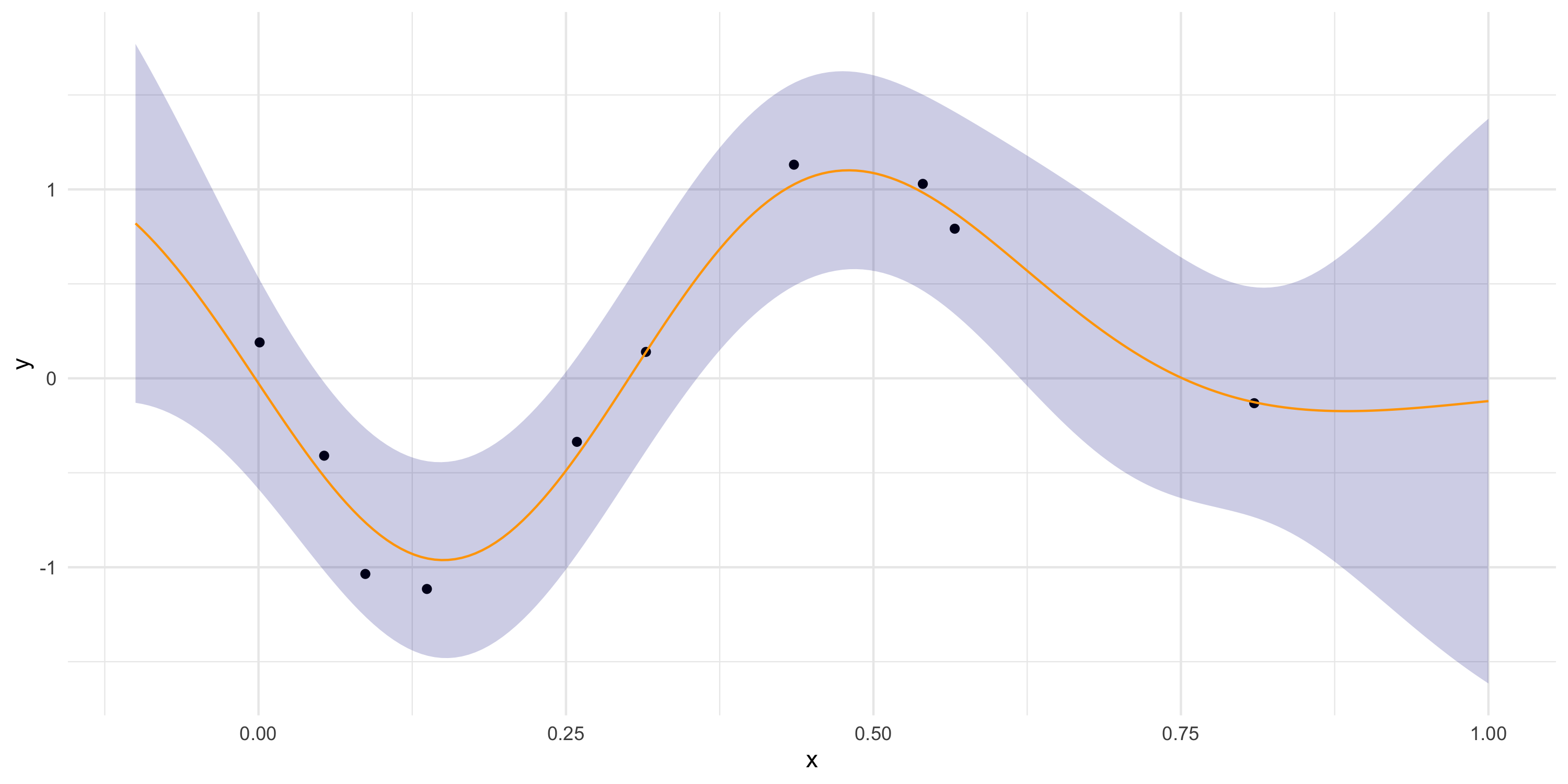
Let’s simplify and consider a 1-dimensional spatial domain and a small dataset
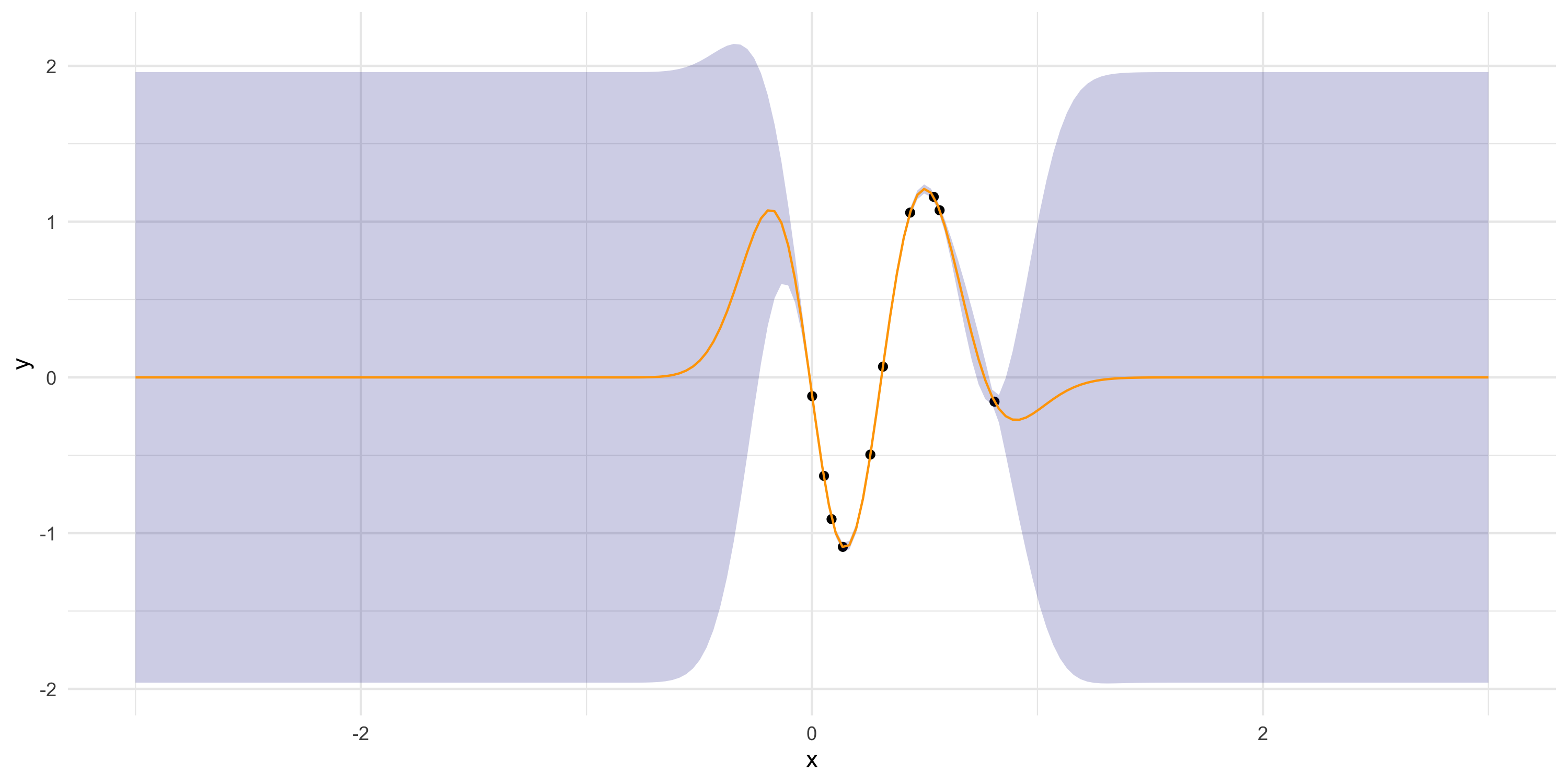
Far from data? Prediction = prior mean of the GP (zero, usually)
More on point predictions
Notice what happens when we increase tausq (now at 0.05)
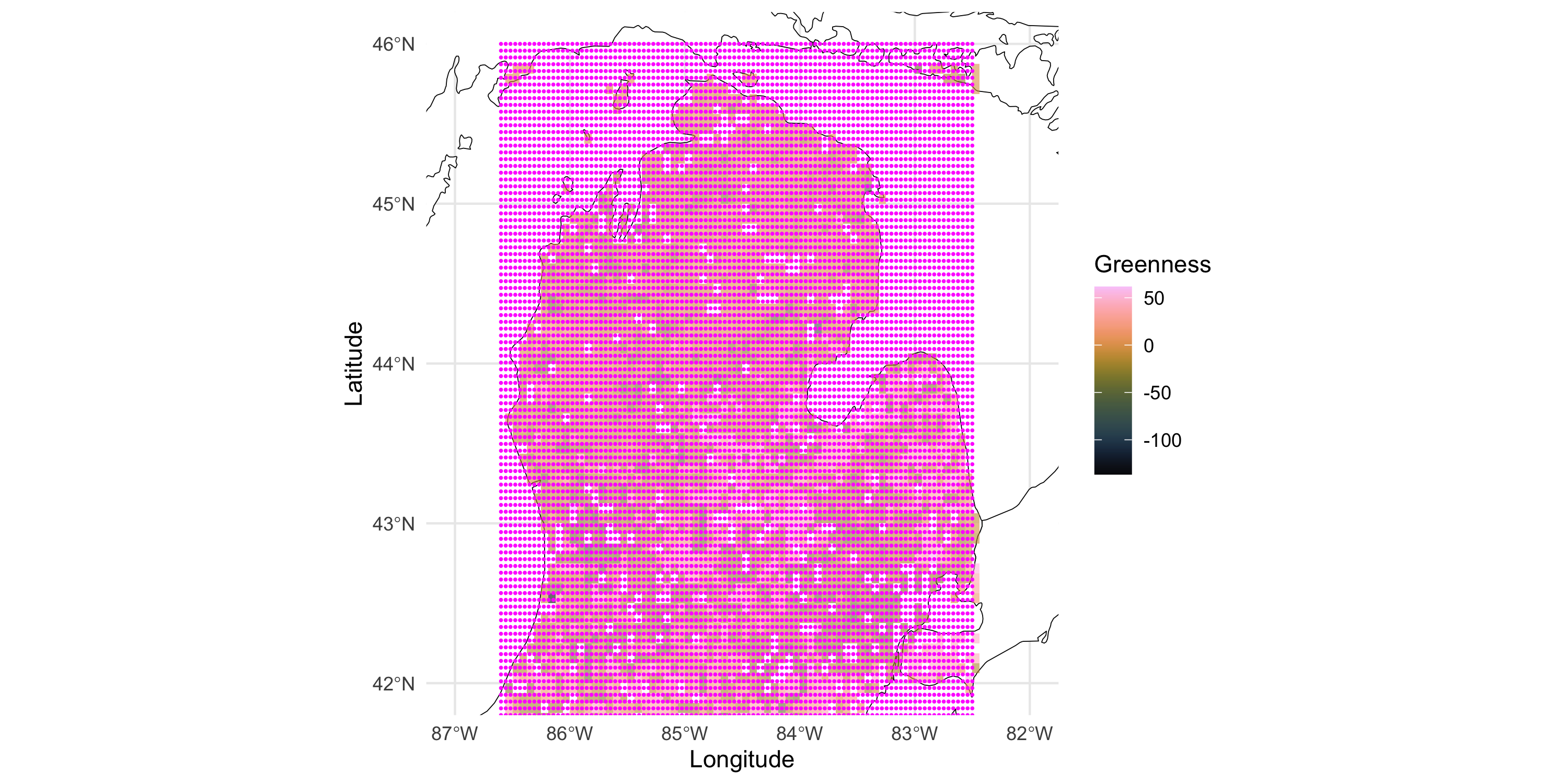
More on uncertainty bands
Uncertainty increases as we move away from the observations
More on uncertainty bands
Far from data? Uncertainty band = prior variance
More on point predictions and uncertainty bands
Notice what happens when we increase tausq (now at 0.05)
Summary
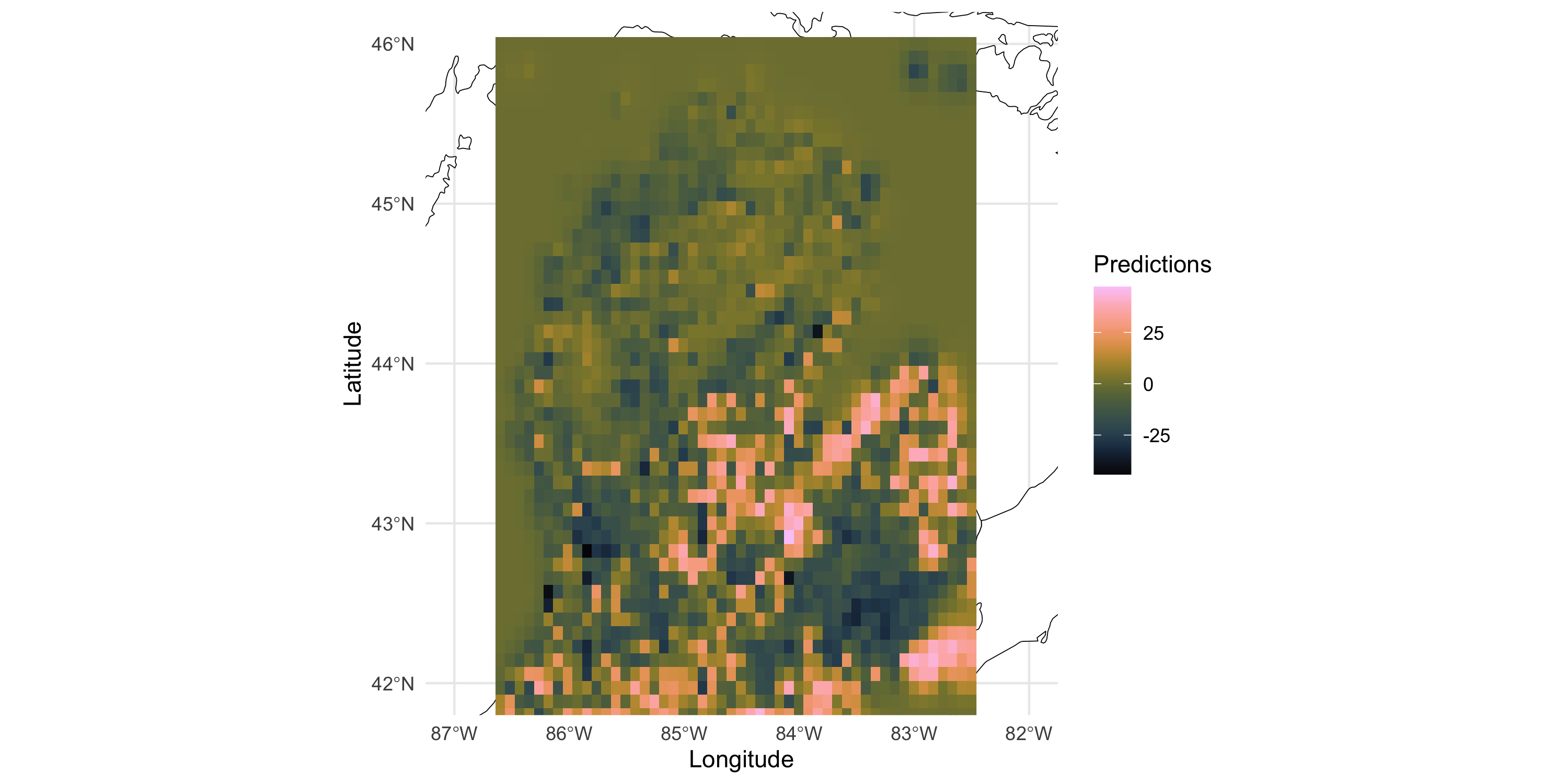
The same things we see in 1 dimension occur in 2 or more dimensions!
As we move away from the observed data
The predictive mean gets closer to the prior mean we have assumed for the GP
Uncertainty bands become wider, up to being equal to the prior variance
This matches the intuition that spatial dependence is determined by distance
When we are far from data, we do not have information to make predictions
We thus revert to our prior information (i.e. our GP assumption)
Because the GP interpolates at the observed locations, it is a flexible model for any dataset
The Gaussian assumption is difficult to criticize when we only have 1 replicate of the data because for any dataset with 1 replicate, the GP will “connect all the points” via interpolation
In the presence of noise, other assumptions can be criticized, such as the choice of the covariance function and its parameters