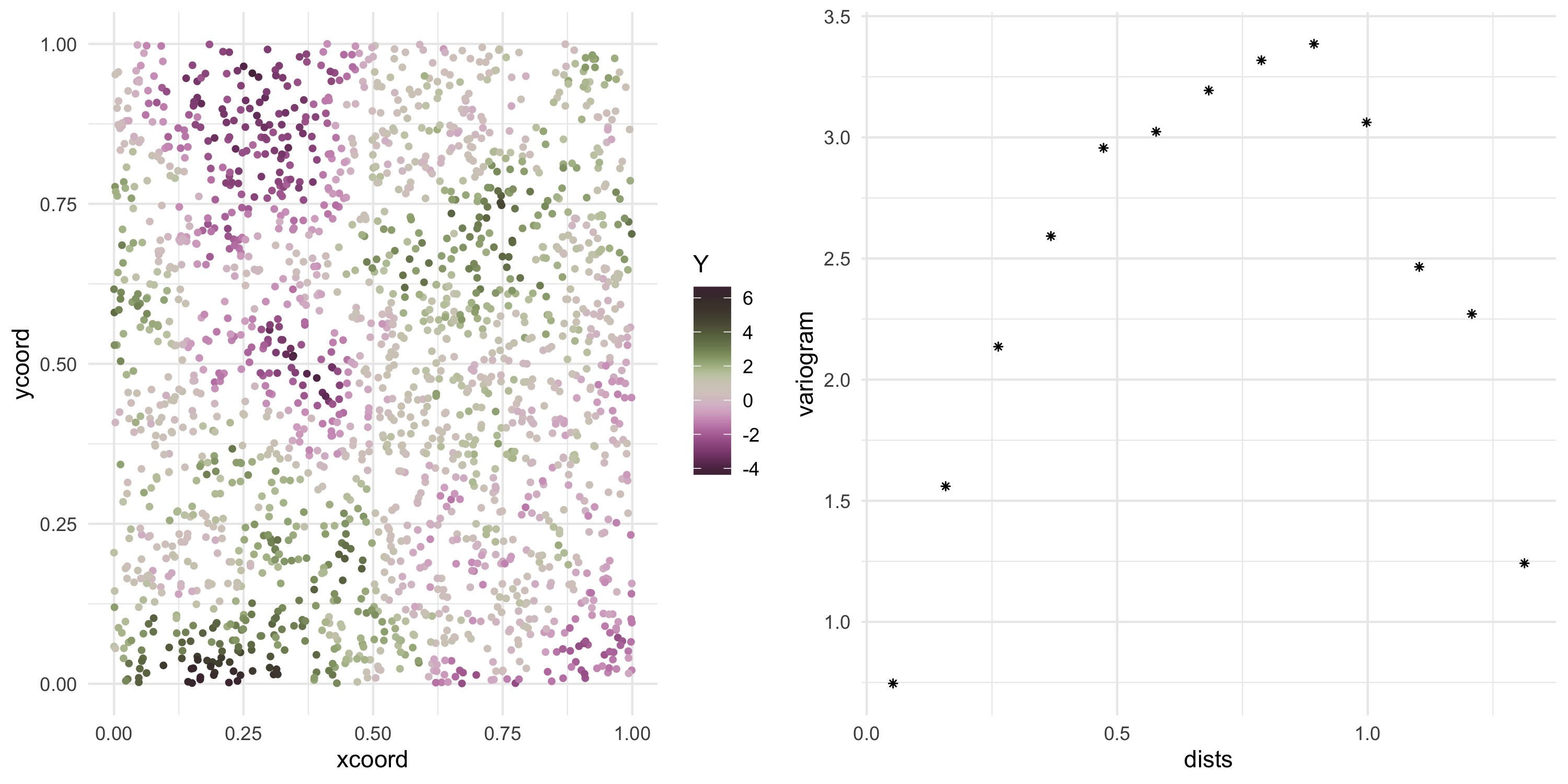
IND is very common when we have replicated data, i.e. multiple observations of the same random variable
IND is inappropriate with spatial data because it assumes there is no dependence at all! We want dependence between random variables that is based on the notion of proximity or distance
The closer in spaceY(s) and Y(s') are, the more they should be dependent on each other
To model spatial data is to model (spatial) dependence within a set of random variables
We have not defined the function C(\cdot, \cdot) yet
C(\cdot, \cdot) tells us all we need to know about how our spatial random variables are dependent with each other. Why?
Building Gaussian Processes
C(\cdot, \cdot) tells us all we need to know about how our spatial random variables are dependent with each other. Why?
Because we have made a Gaussian assumption
Covariance matrix completely defines a mean-zero MVN
Covariance function tells us how to build a covariance matrix on any set of locations
GP modeling boils down to covariance modeling
Our assumptions on C(\cdot, \cdot) will direct our inference
Typically, C(\cdot, \cdot) is a parametric function of a small number of unknown parameters
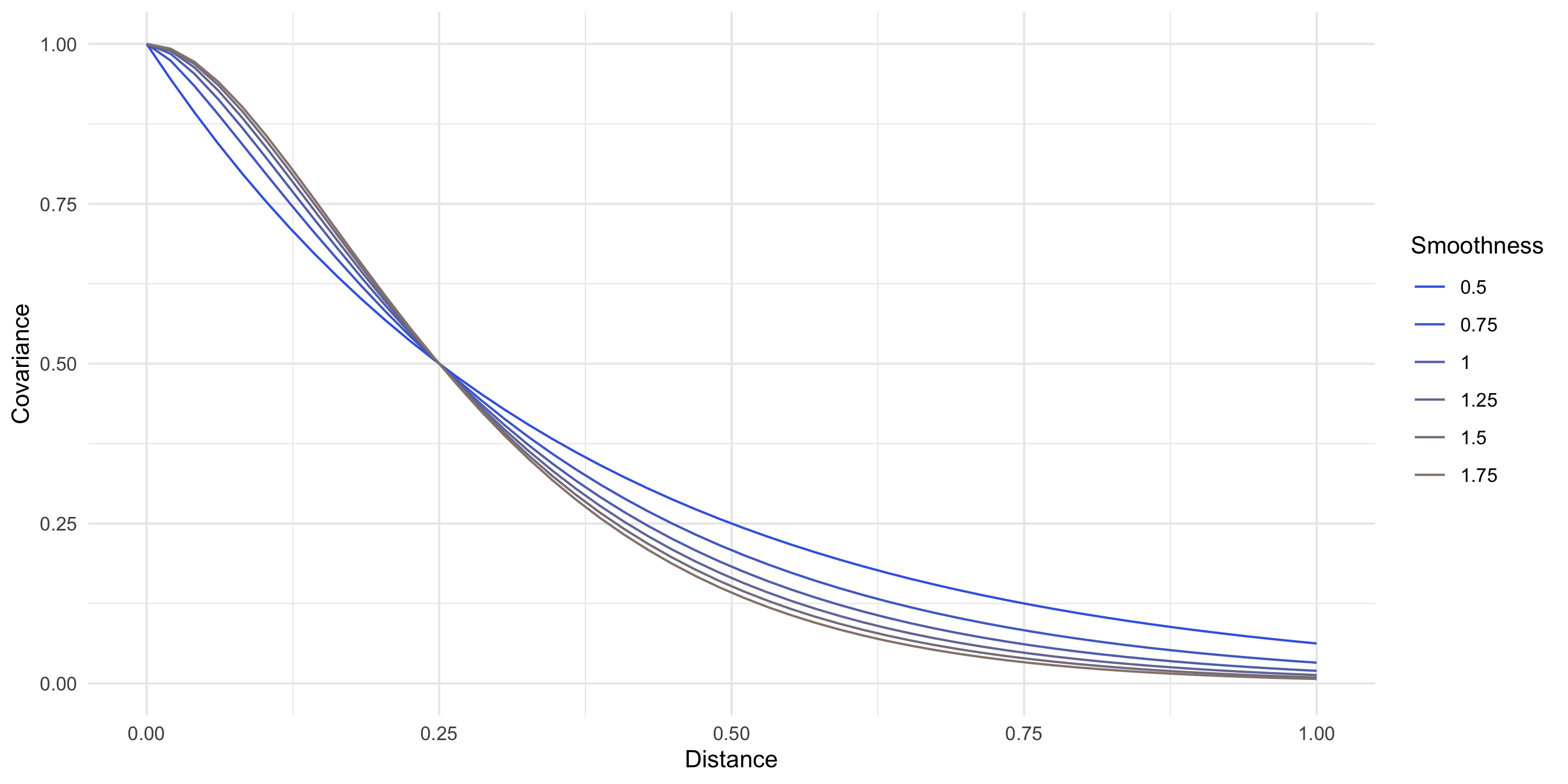
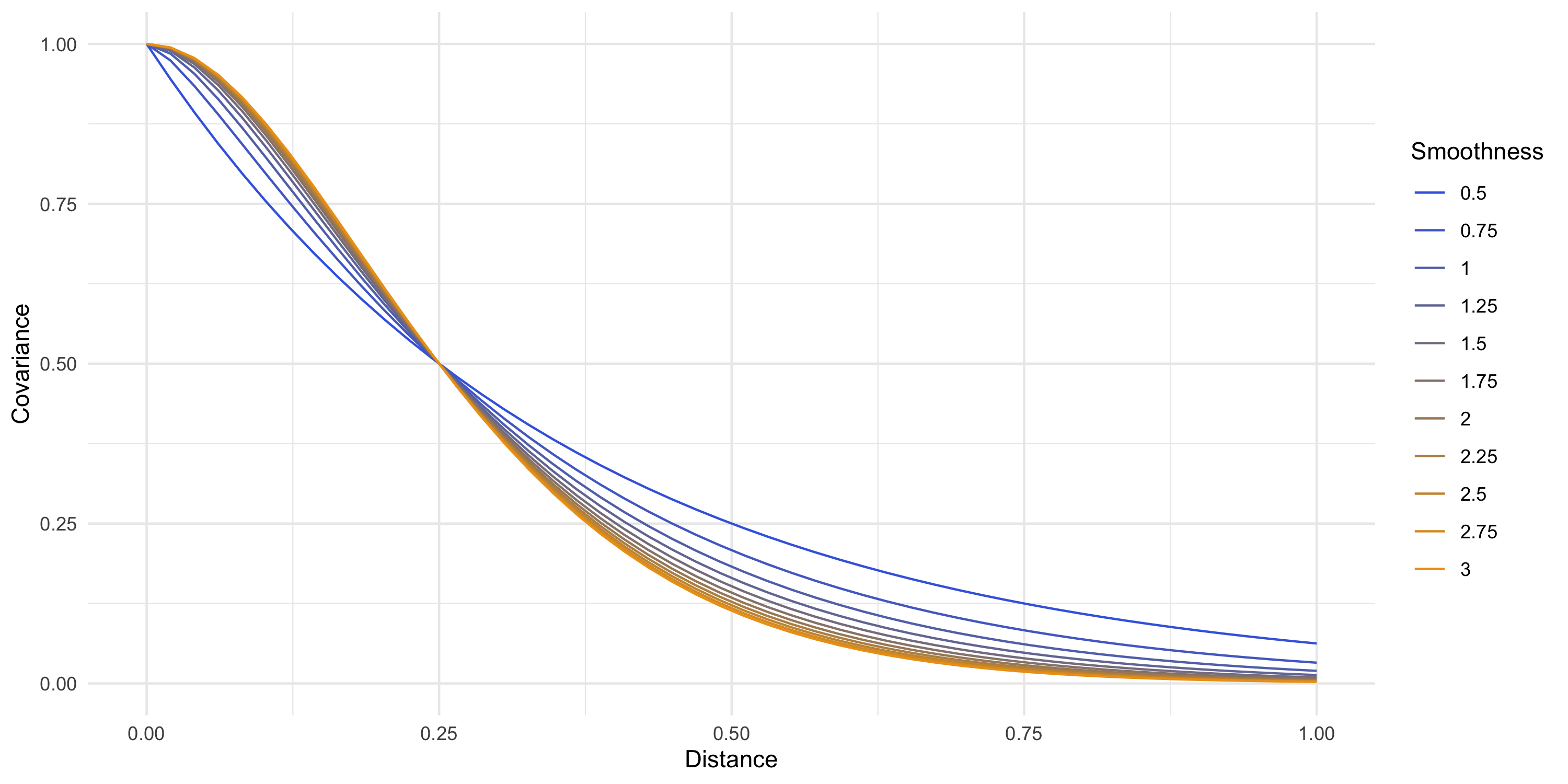
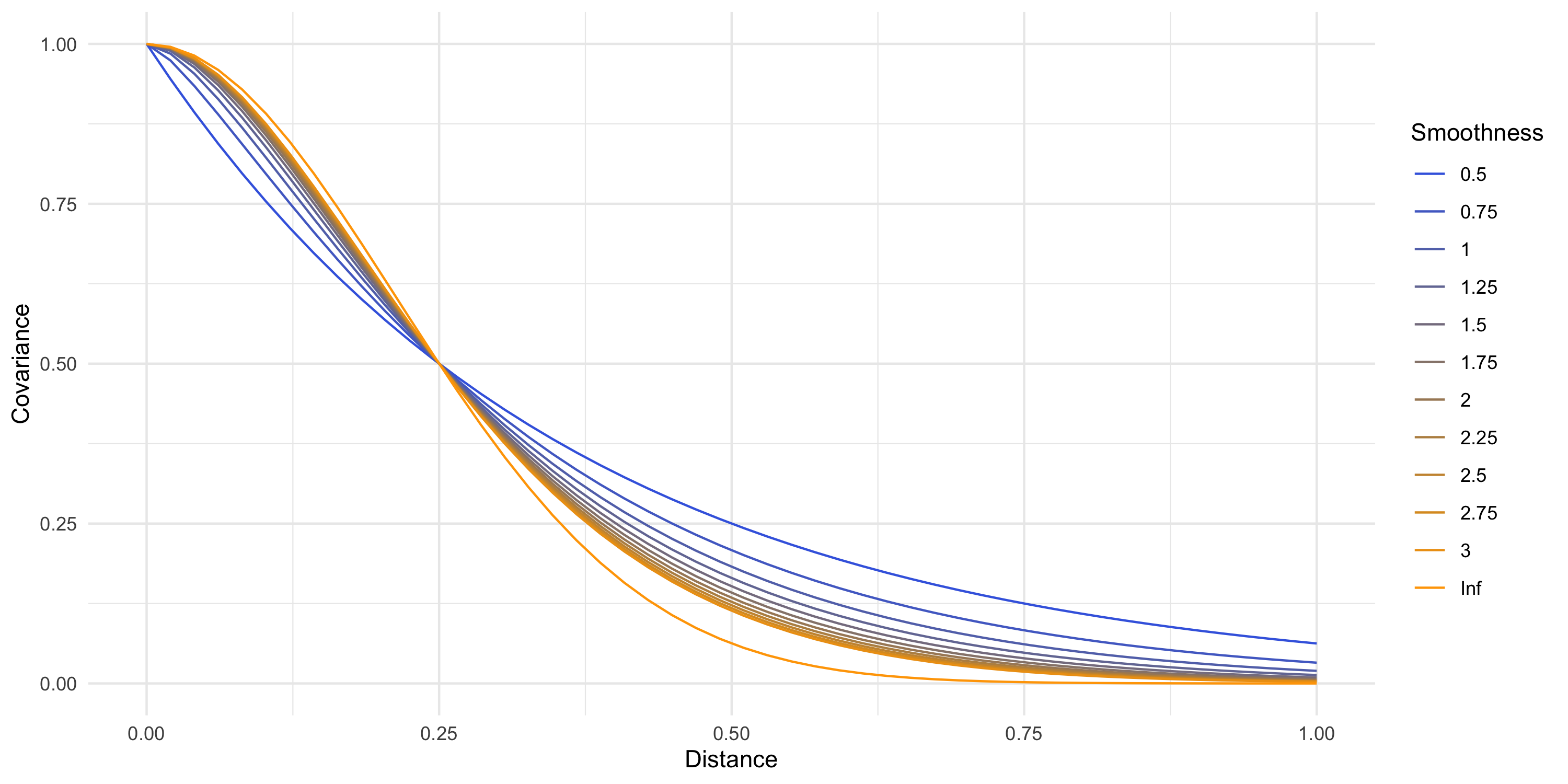
Covariance parameters describe the underlying process’s variance, smoothness, spatial range
Let \theta be a vector of covariance parameters, then we can write our covariance function as C_{\theta}(\cdot, \cdot)
Covariance function vs Covariance between random variables
Note we are constructing a covariance function that takes pairs of spatial locations as inputs
We use that function to model the covariance between random variables at that pair of spatial locations
In other words we are making this assumption:
Cov(Y(s), Y(s')) = f(s, s') for some function f of our choice. In other words we model covariance uniquely via the random variables’ spatial locations.
Compute Cholesky decomposition of covariance matrix C
L <-t(chol(C)) # chol() computes upper cholesky U=t(L), C = crossprod(U) = tcrossprod(L)
Sample the MVN
Y <- L %*%rnorm(nobs) +0.1*rnorm(nobs)
Plot the data
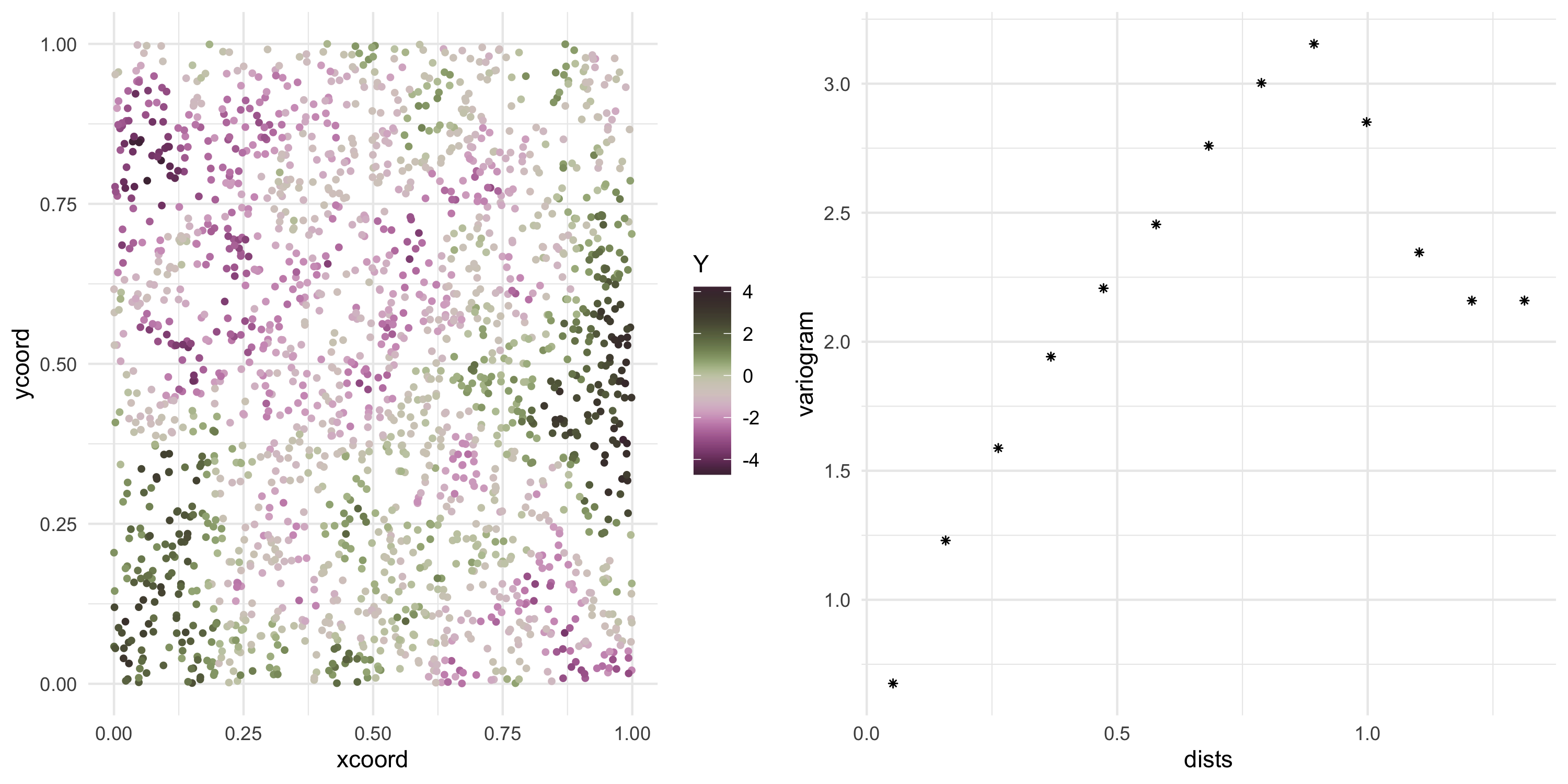
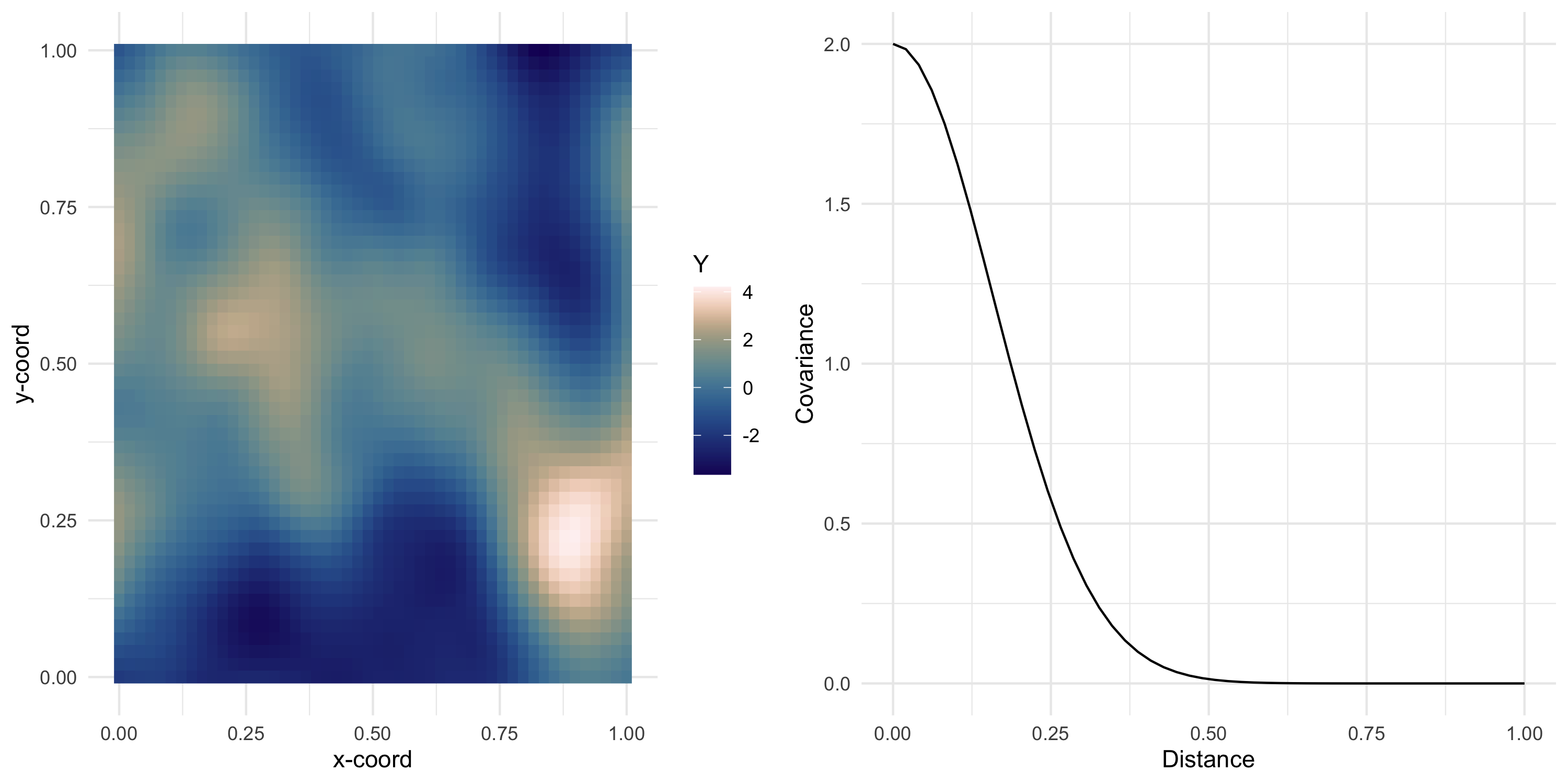
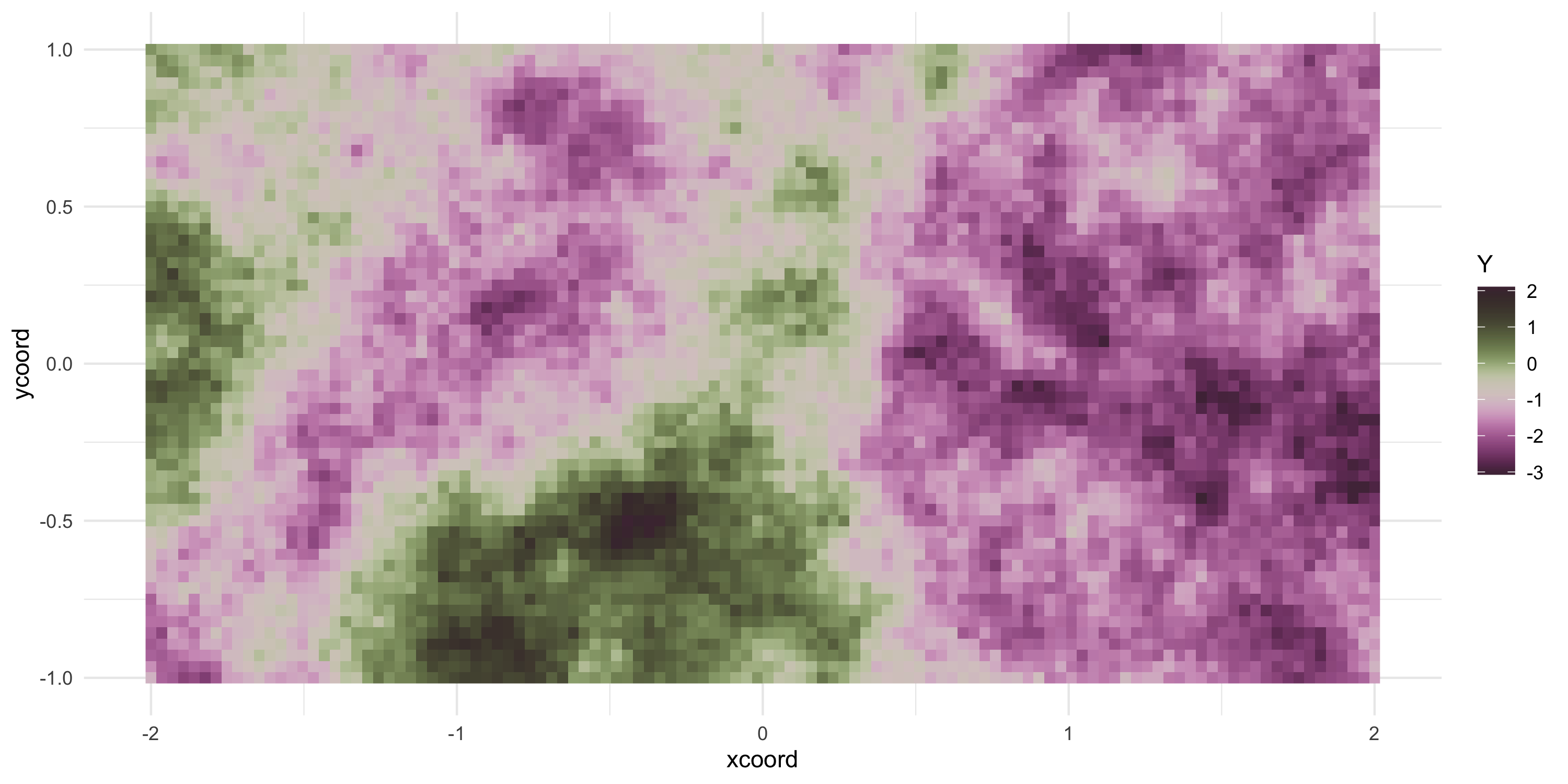
Exponential covariance model
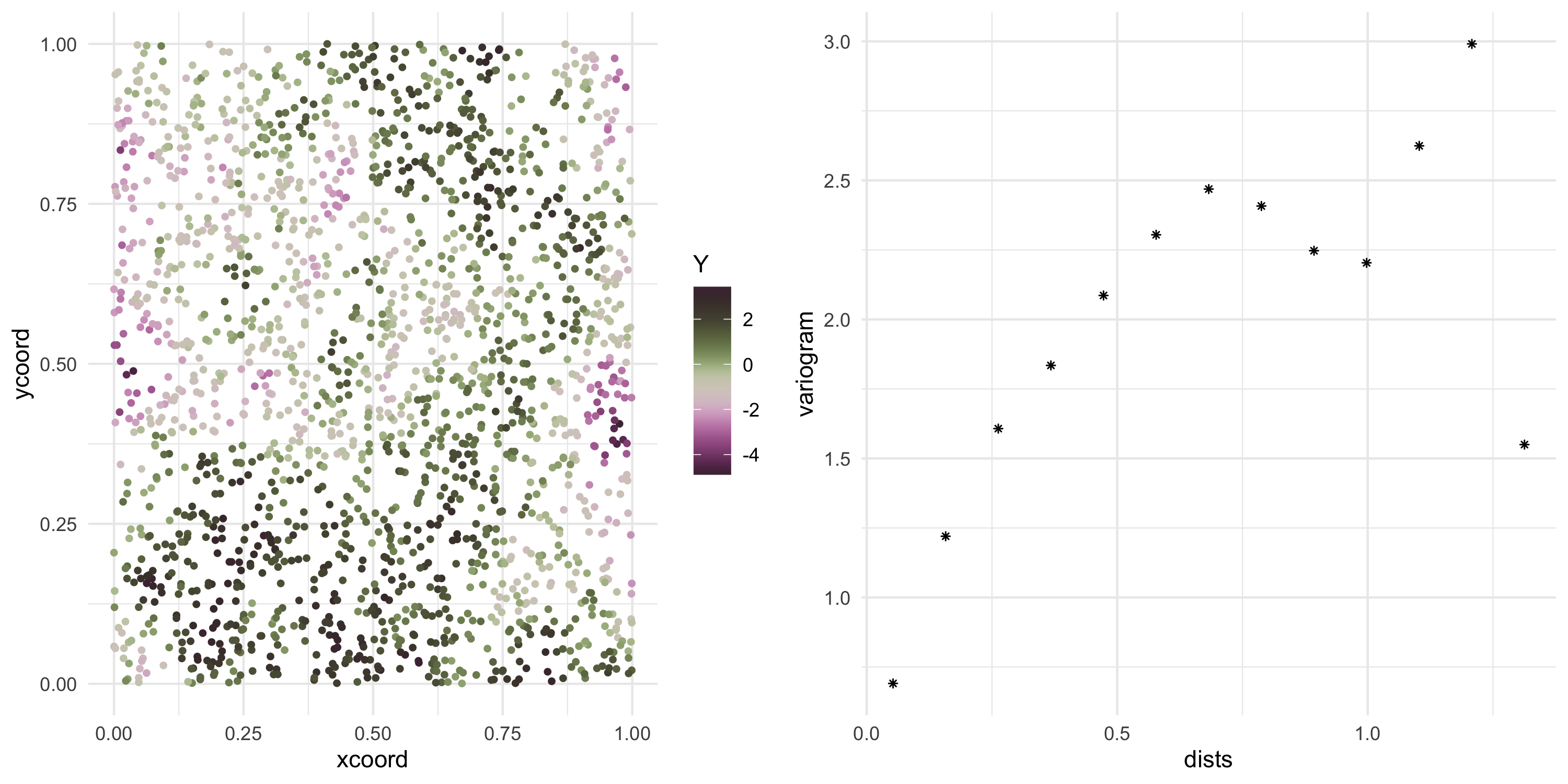
Now we can keep sampling from the same Gaussian Process
Y <- L %*%rnorm(nobs)
Plot the data
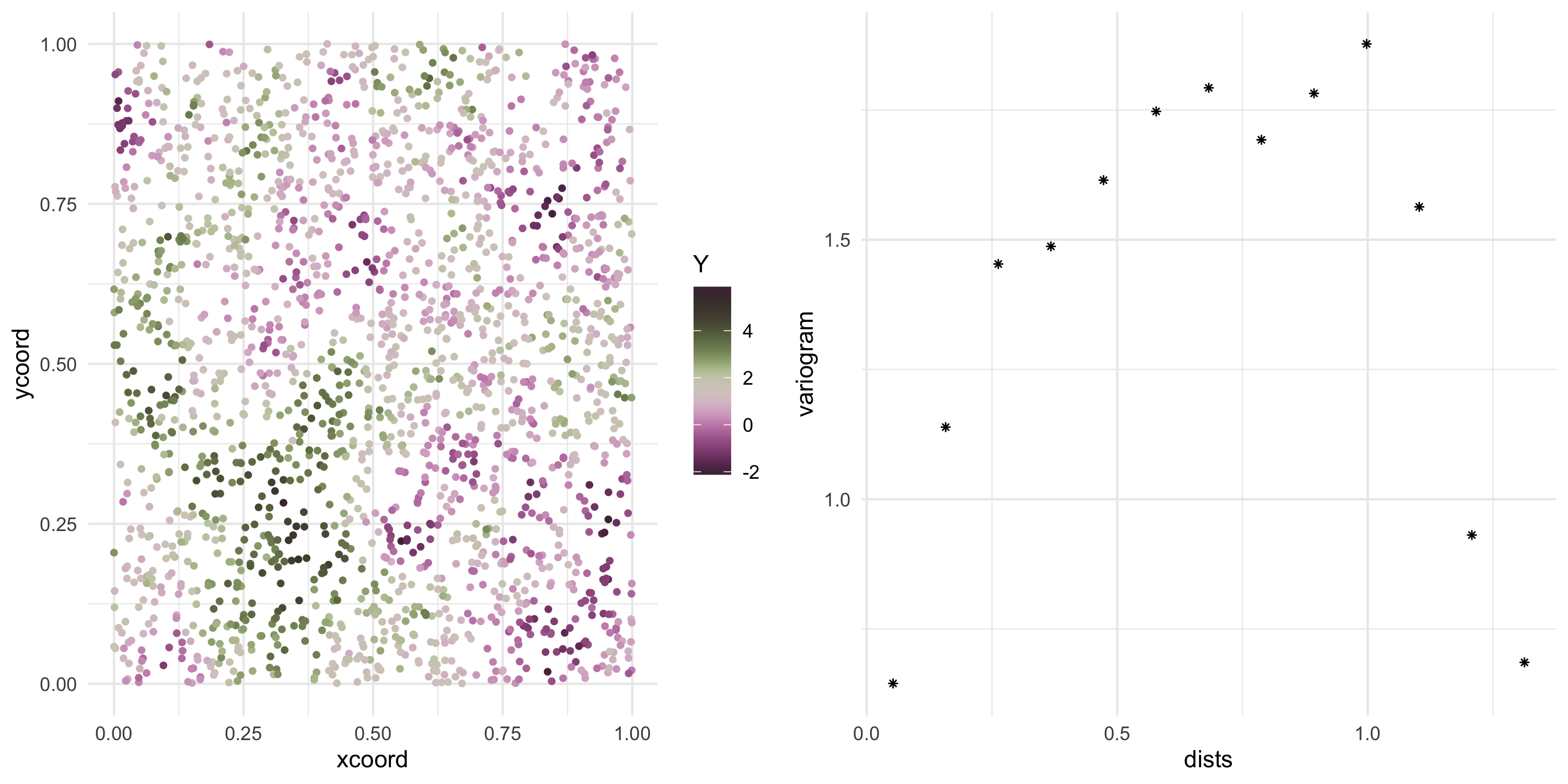
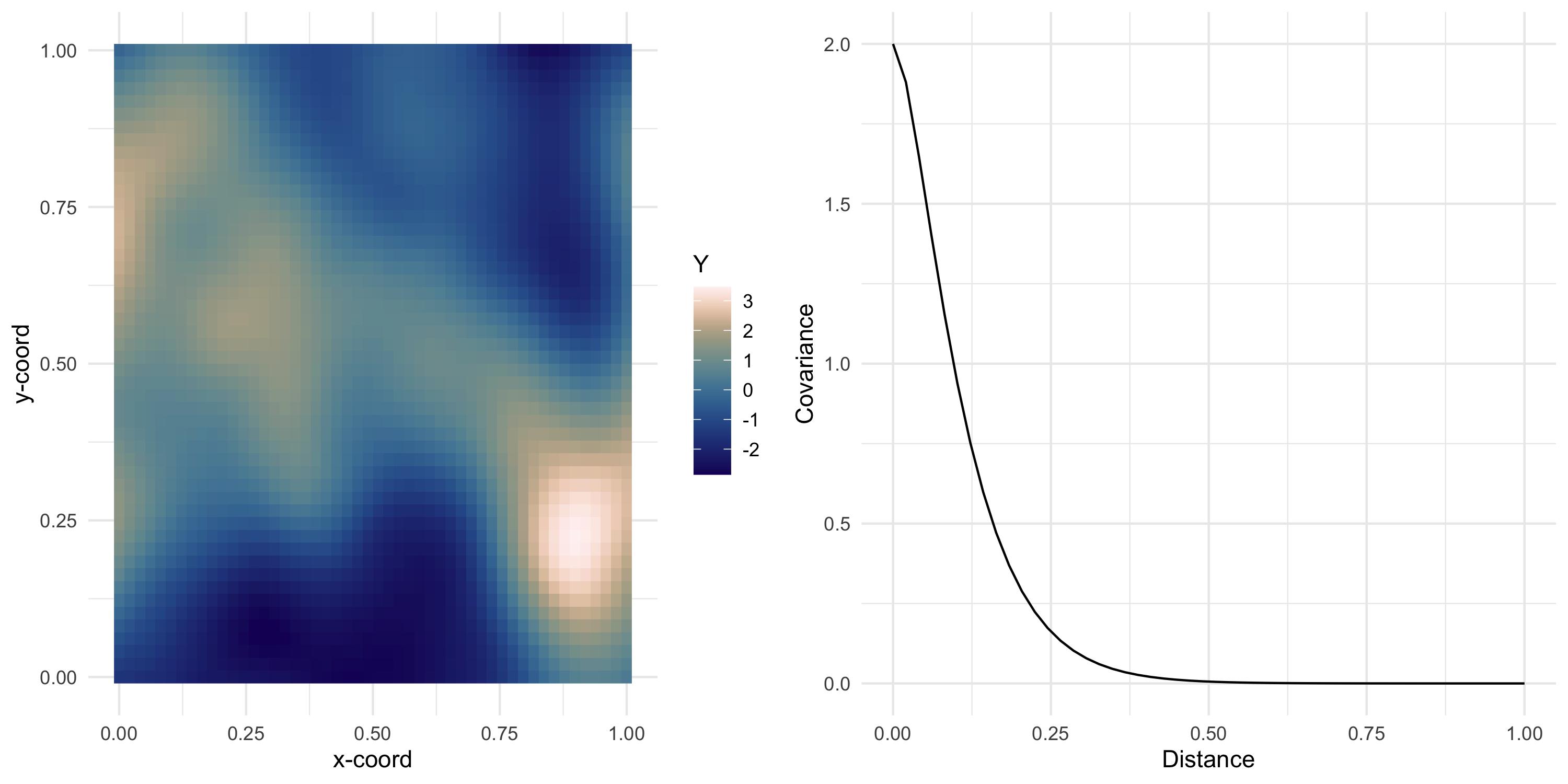
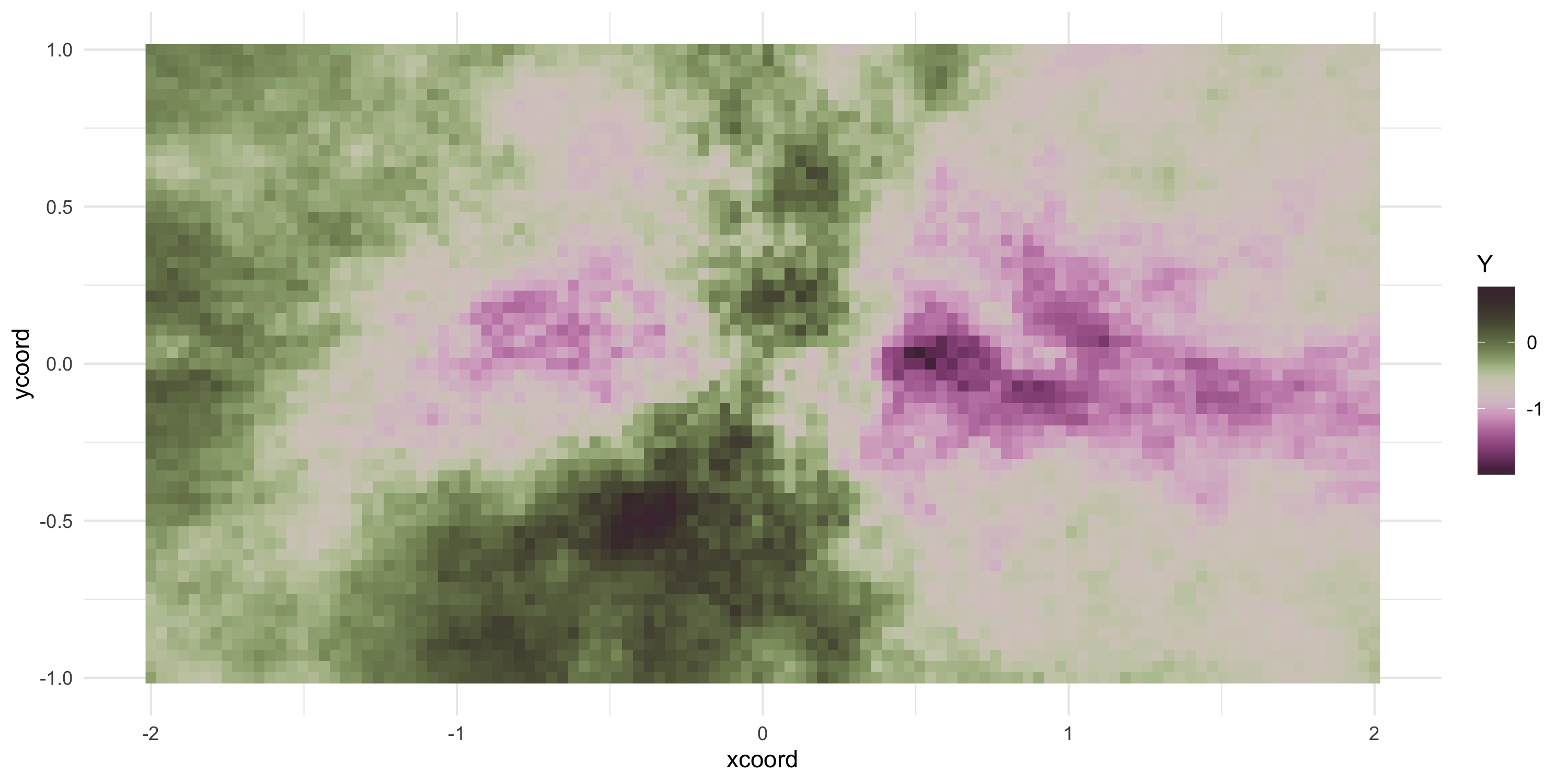
Exponential covariance model
Now we can keep sampling from the same Gaussian Process (at the same locations)
Y <- L %*%rnorm(nobs)
Plot the data
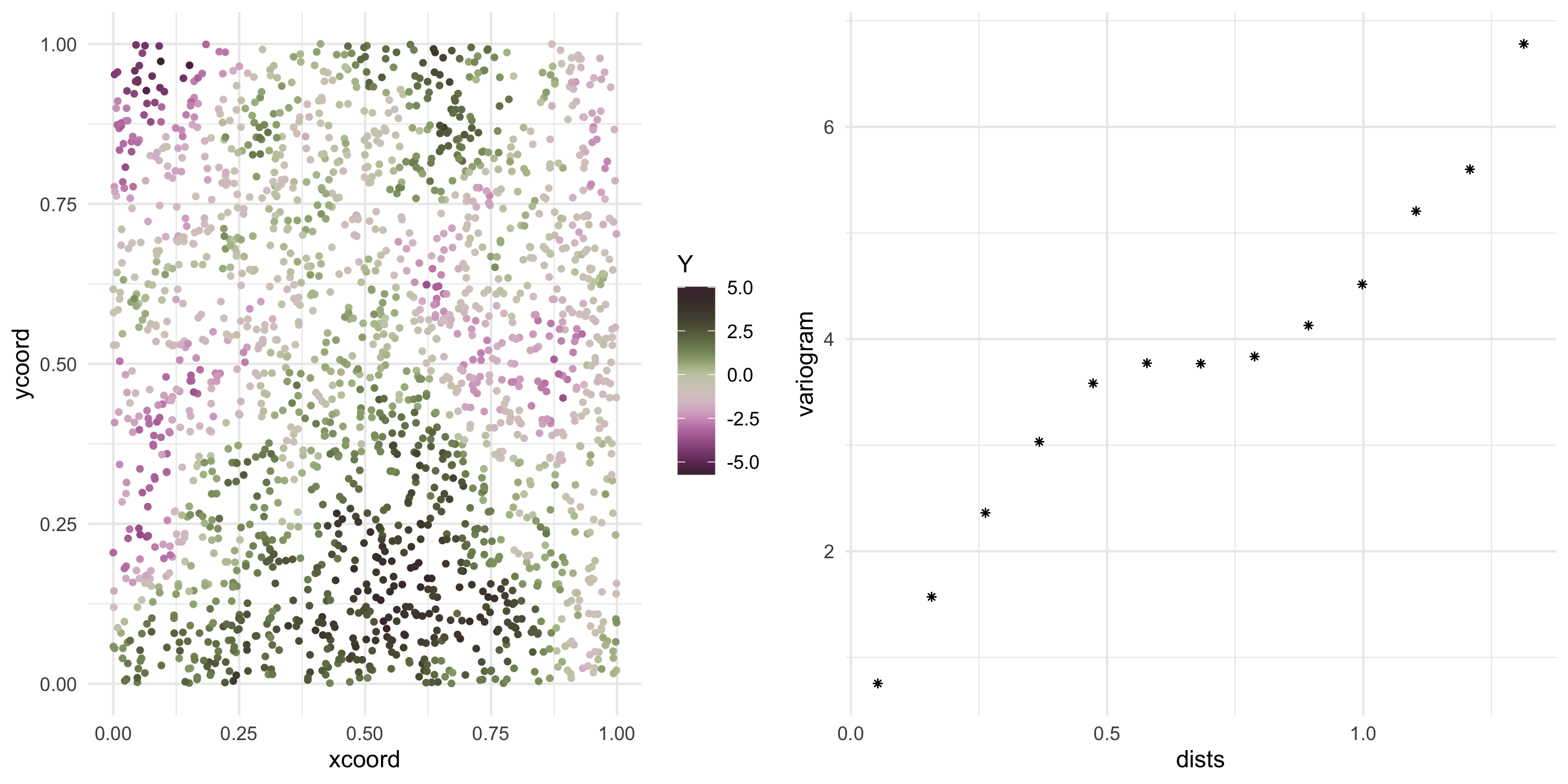
Exponential covariance model
Now we can keep sampling from the same Gaussian Process (at the same locations)
Y <- L %*%rnorm(nobs)
Plot the data
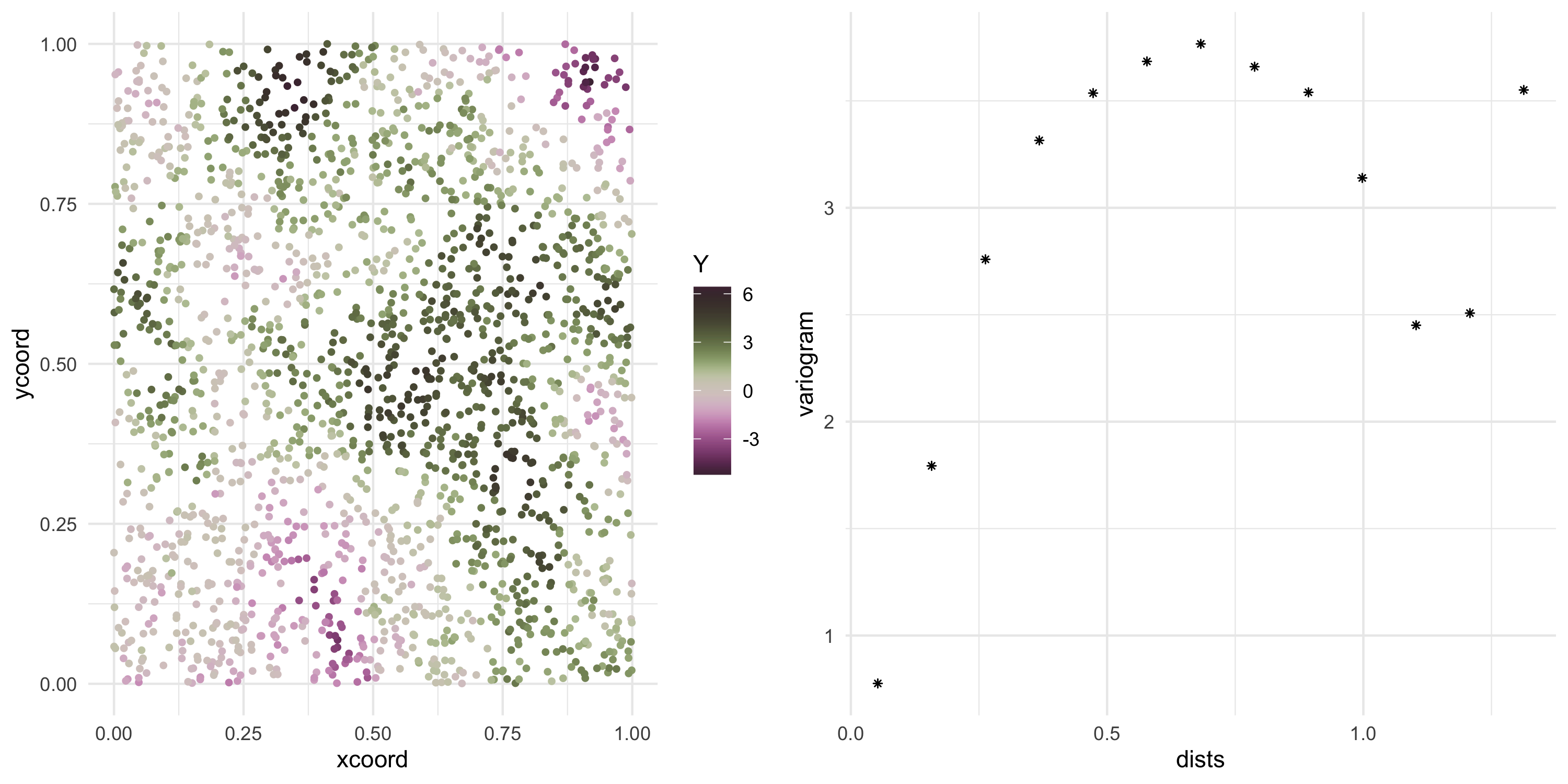
Exponential covariance model
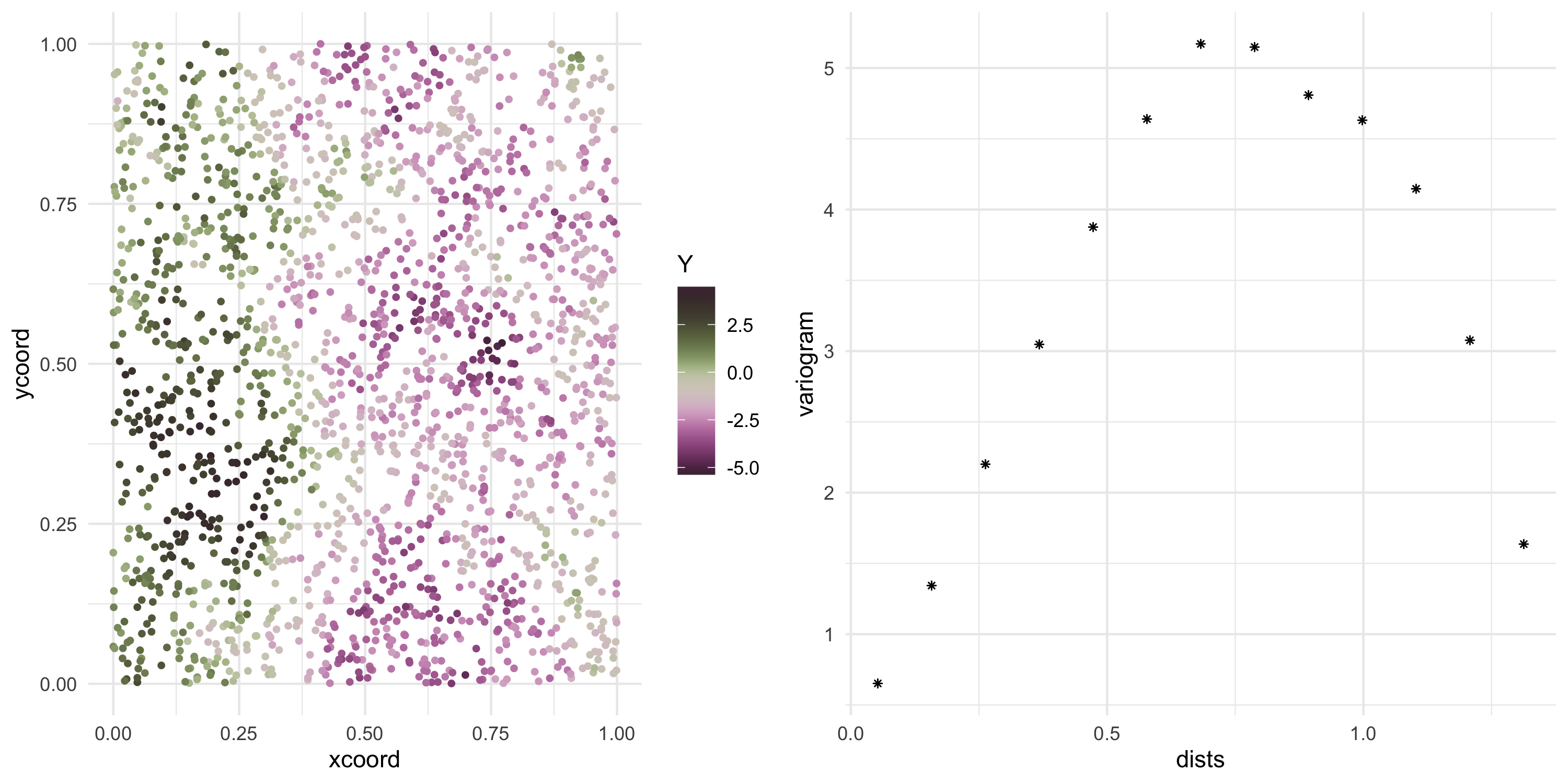
Now we can keep sampling from the same Gaussian Process (at the same locations)
Y <- L %*%rnorm(nobs)
Plot the data
Exponential covariance model
Now we can keep sampling from the same Gaussian Process (at the same locations)
Y <- L %*%rnorm(nobs)
Plot the data
Exponential covariance model
Now we can keep sampling from the same Gaussian Process (at the same locations)
Y <- L %*%rnorm(nobs)
Plot the data
Stationary covariance functions
C(\cdot, \cdot) is stationary if C(s, s + h) = C(h) for all h \in \Re^d such that s, s+h \in D
In other words, covariance only depends on the separation vector h
In other words, C(s, s') = C(s-s'), we are modeling covariance as not depending on the absolute location of s and s' but only their relative position in the spatial domain
Isotropic covariance functions
C(\cdot, \cdot) is isotropic if C(s, s + h) = C(||h||) for all h \in \Re^d such that s, s+h \in D
In other words, covariance only depends on the length of the separation vector h
In other words, C(s, s') = C(||s-s'||), we are modeling covariance as not depending on the absolute location of s and s' but only their relative position in the spatial domain, without regard to orientation
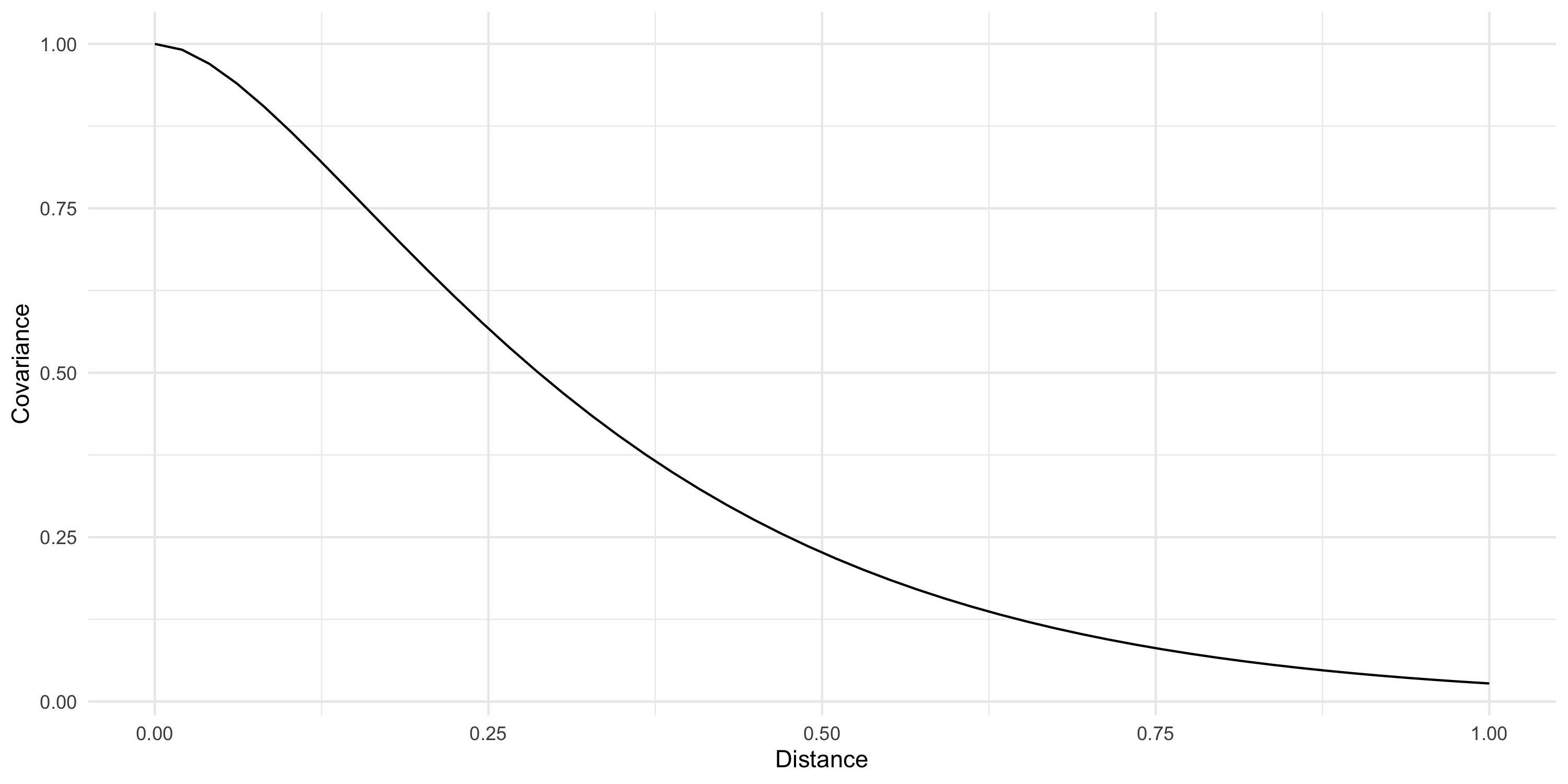
We can write C(s, s')=C(d) where d = ||s-s'|| is the distance between s and s'
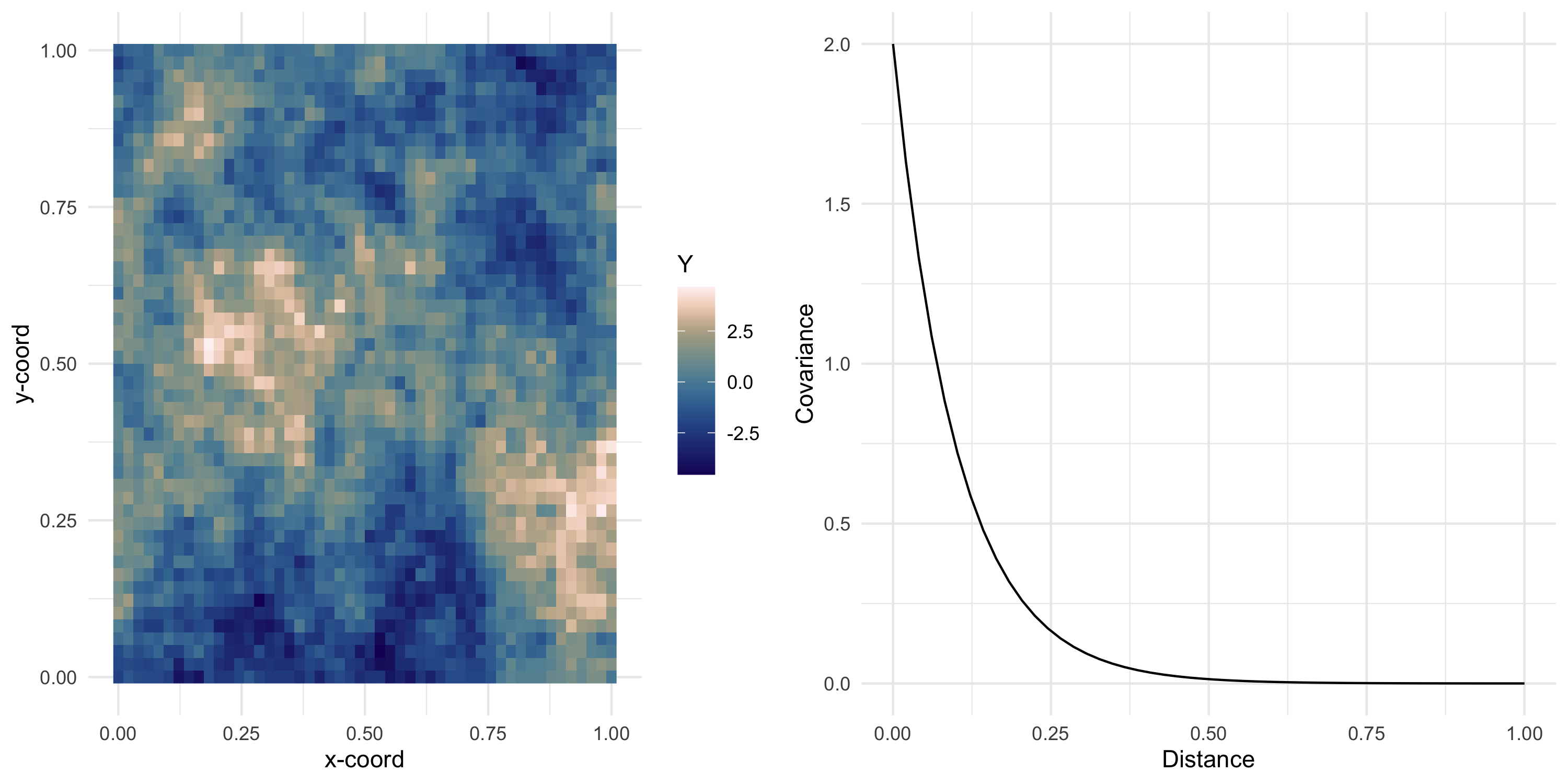
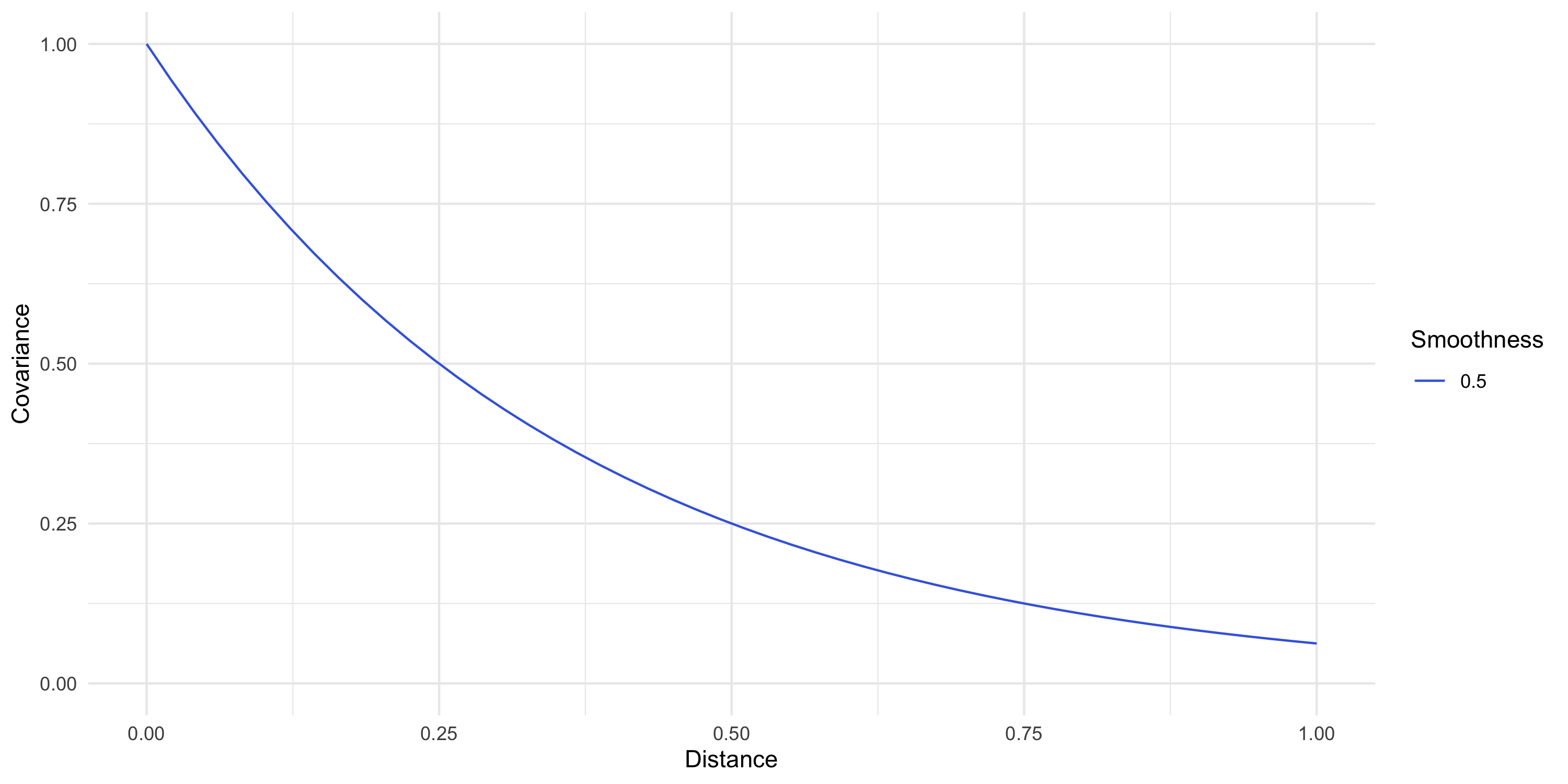
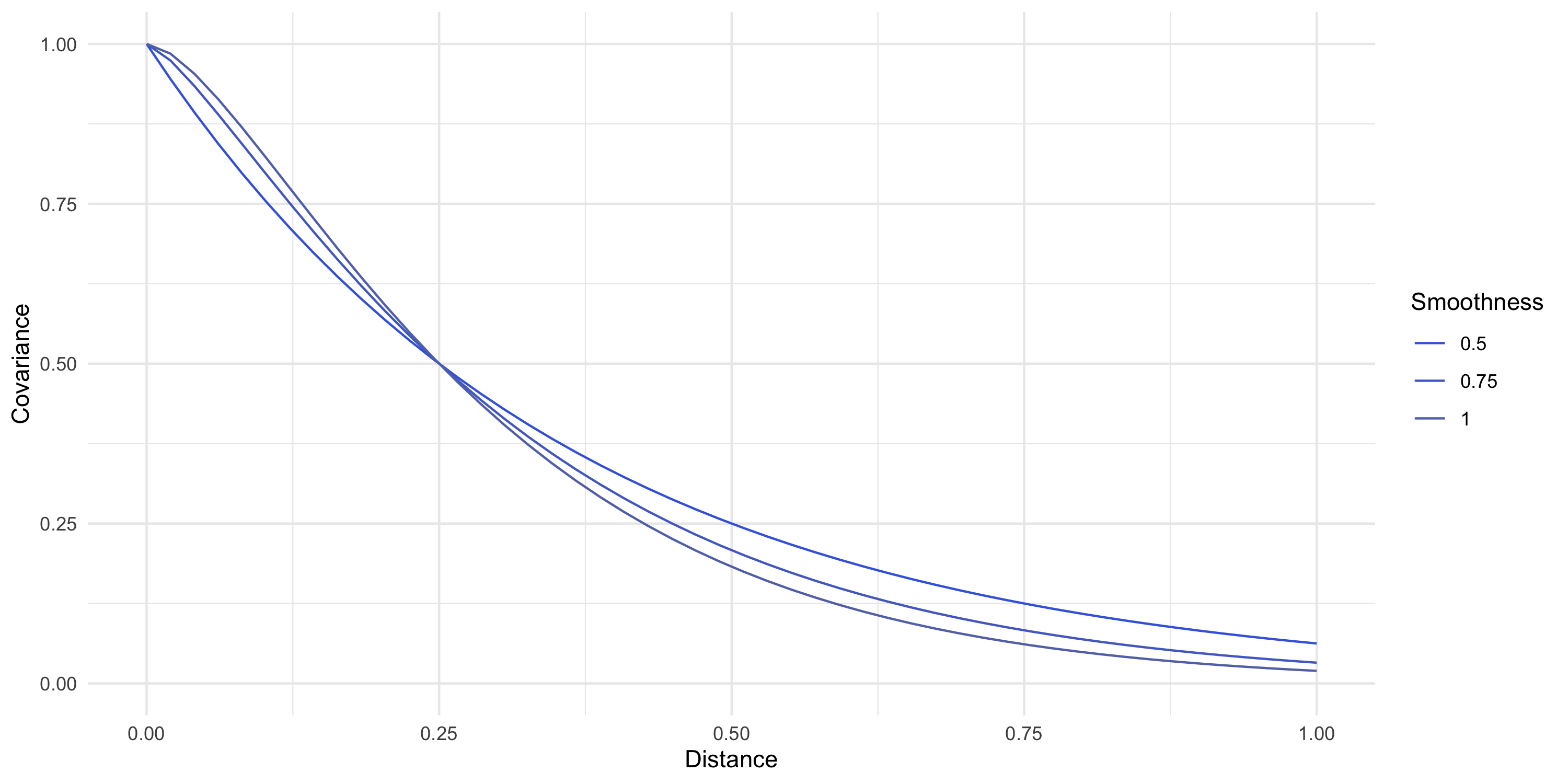
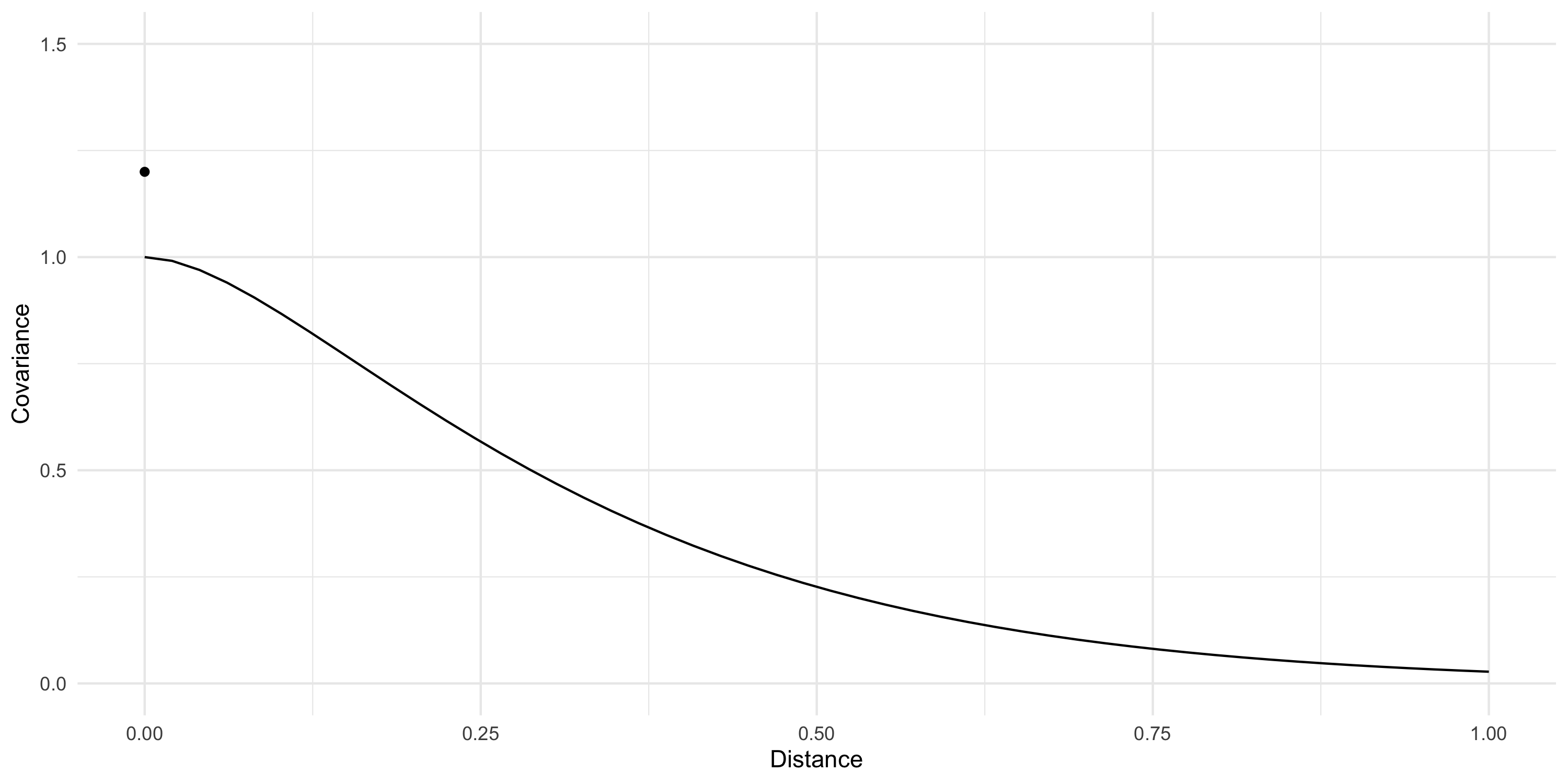
Example: Exponential covariance
C(d) = \sigma^2 \exp \{ -\phi d \}
\phi is the spatial decay parameter. Sometimes we use \alpha=1/\phi, called the range
The matrix L_A L_A^T is symmetric positive definite by construction
If l_{21} = l_{22} = 1 then L_A L_A^T = I_d and we are back to the isotropic case
But this is not very interpretable. How do we assign a “meaning” to l_{11} and l_{22}?
Instead, define S = \text{diag}\{ \sqrt{\phi}, \sqrt{s \phi} \}, R = \begin{bmatrix} 1 & \rho \\ \rho & 1 \end{bmatrix}, where s, \phi > 0, -1<\rho<1. Then C(h) = \sigma^2 \exp \left\{ - (h^T S R S h )^{\frac{\gamma}{2}} \right\}
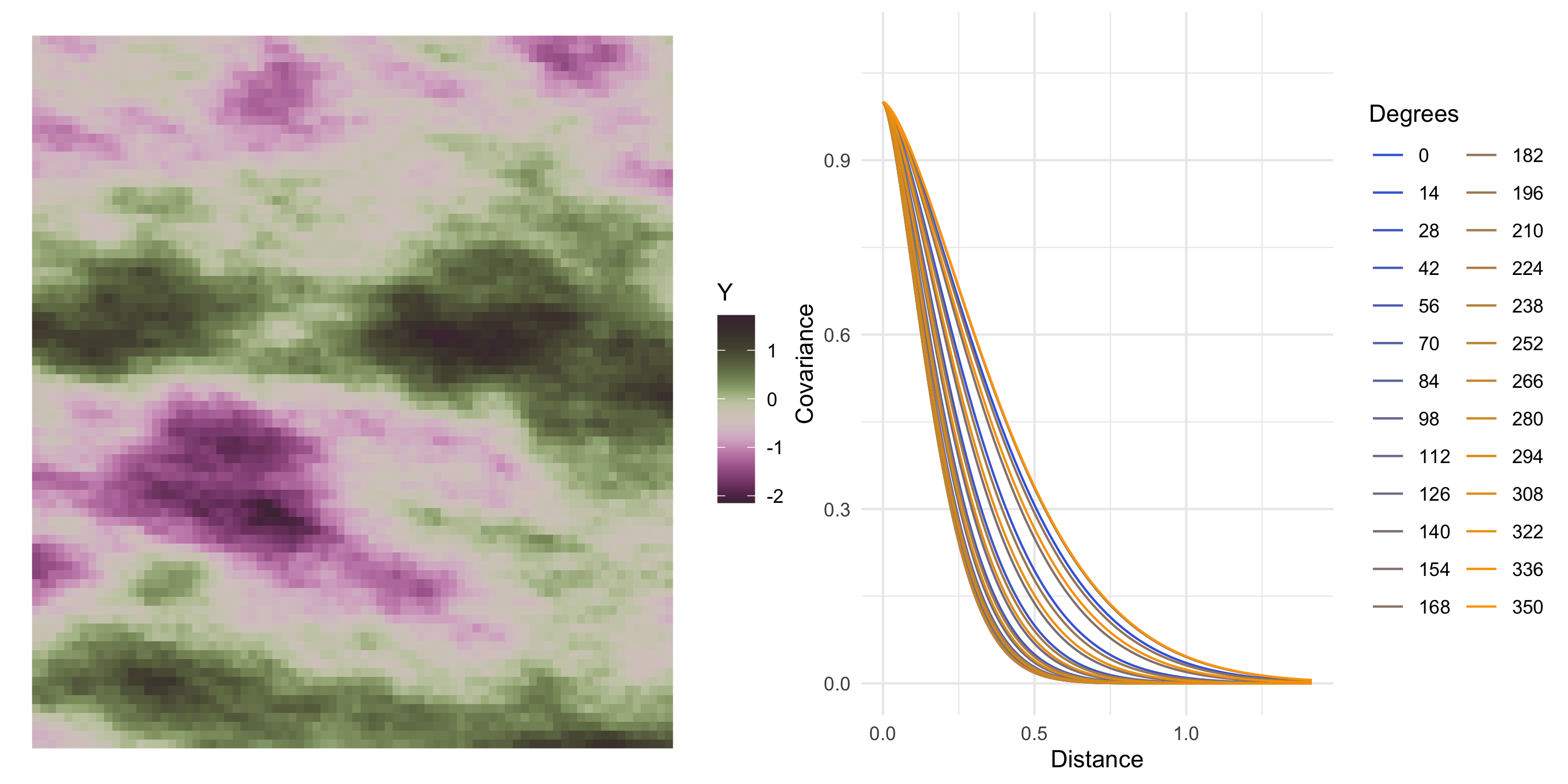
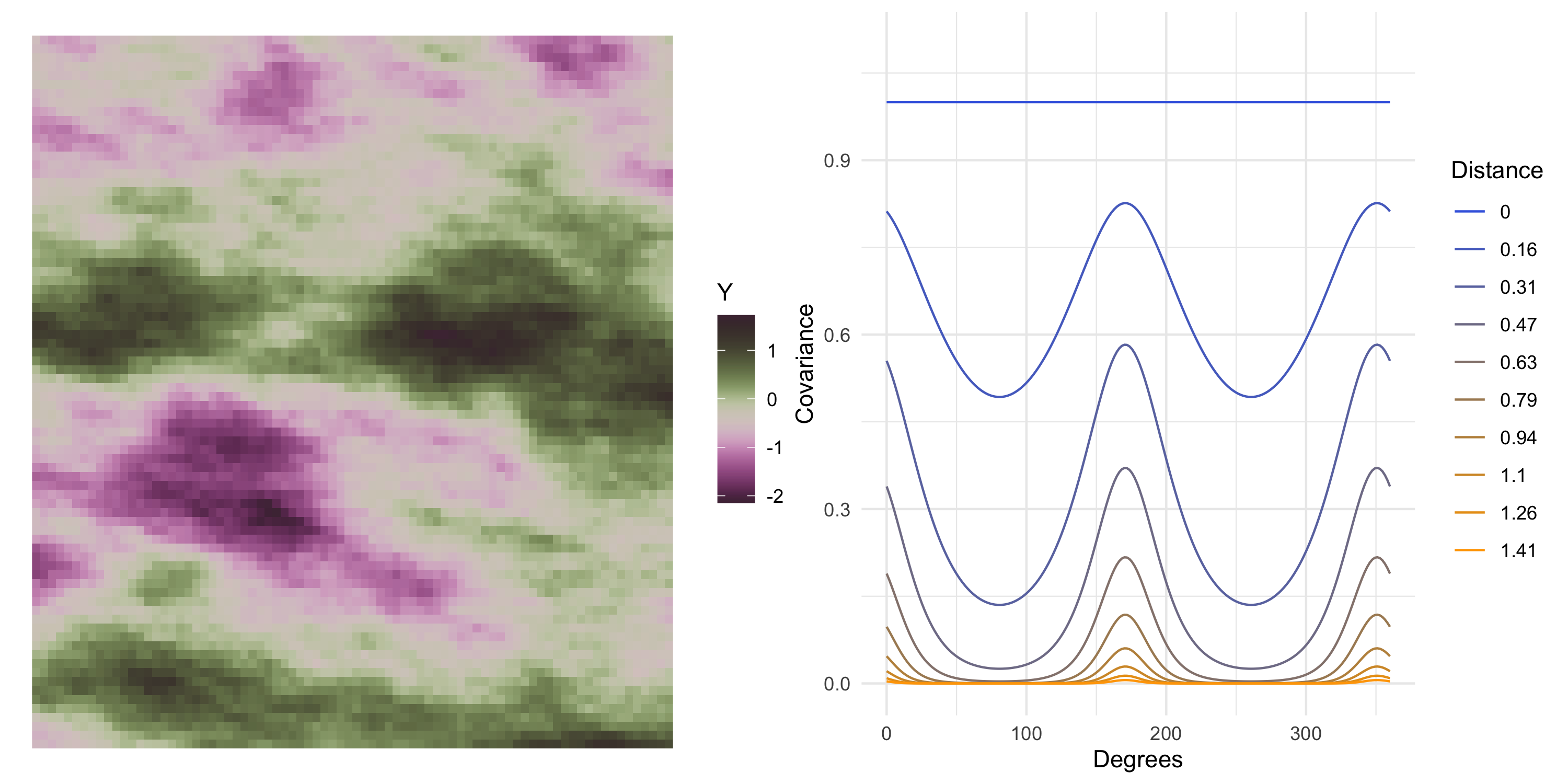
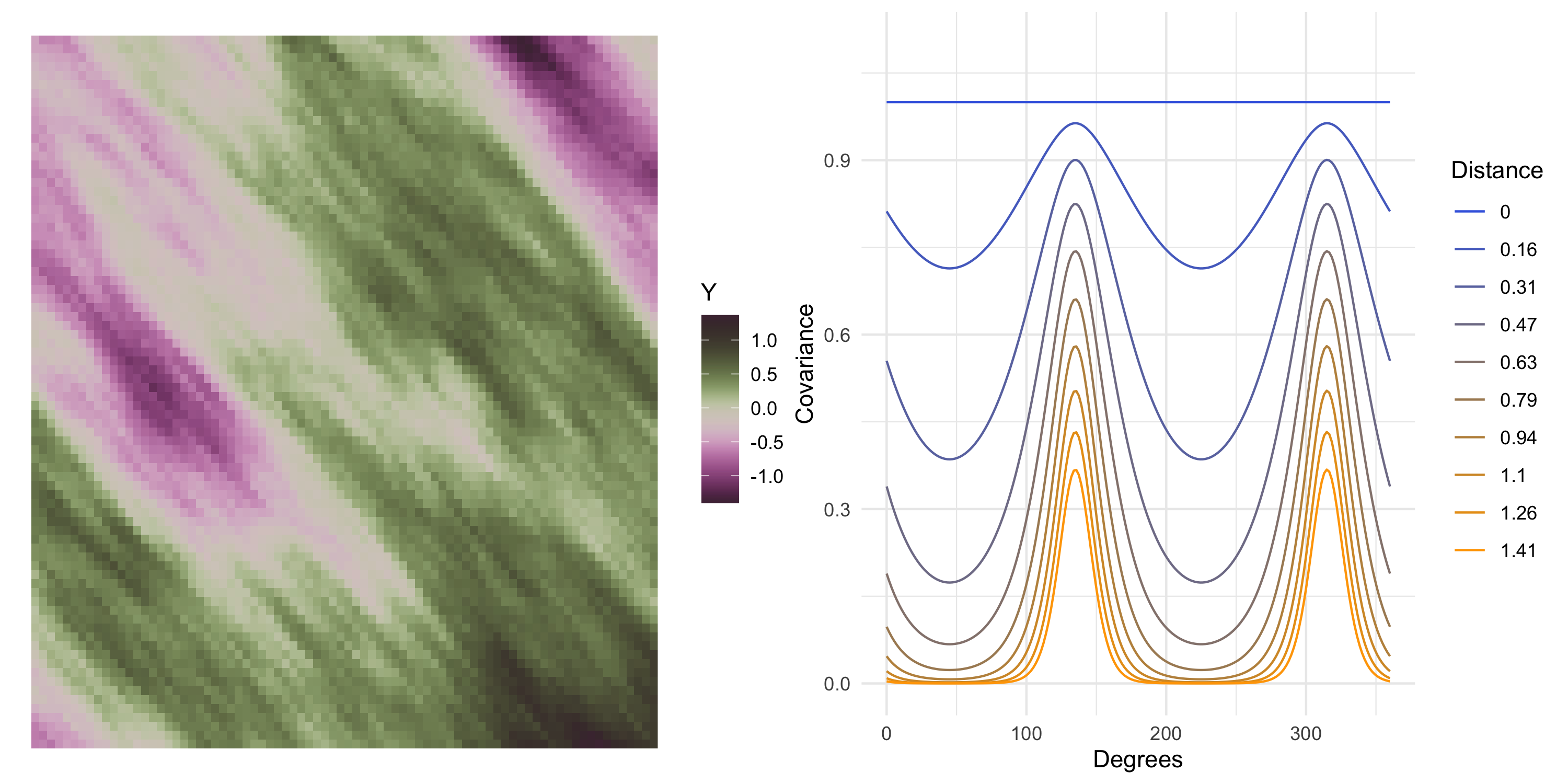
Visualizing a stationary anisotropic covariance function
In the stationary anisotropic cases we considered earlier, C(s, s') depended on the magnitude of s-s' (ie the distance between s and s') as well as the orientation
Therefore there is at least one new dimension to the plot
Visualizing a stationary anisotropic covariance function
Discuss ideas for making covariance plots of nonstationary covariance models
No specific model in mind, just think of what nonstationary implies
Interpretation of covariance models
One reason we choose a specific covariance model is because we think it is a good model of spatial variation in the data
Another reason we choose a specific covariance model is to be able to interpret the results of our estimation
There is a tradeoff between ease of estimation, interpretation, and flexibility to realistic assumptions
Parameters themselves are not always directly interpretable
Different covariance functions’ parameters may not be directly comparable in how they are interpreted
Covariance plot is an effective tool for interpretation
Covariance plot becomes more difficult to do the more the covariance function is complicated!
Interpretation of covariance models
Other questions that we could answer:
what is the signal-to-noise ratio?
how far do we need to take two locations in order for their correlation to be less than 0.95?
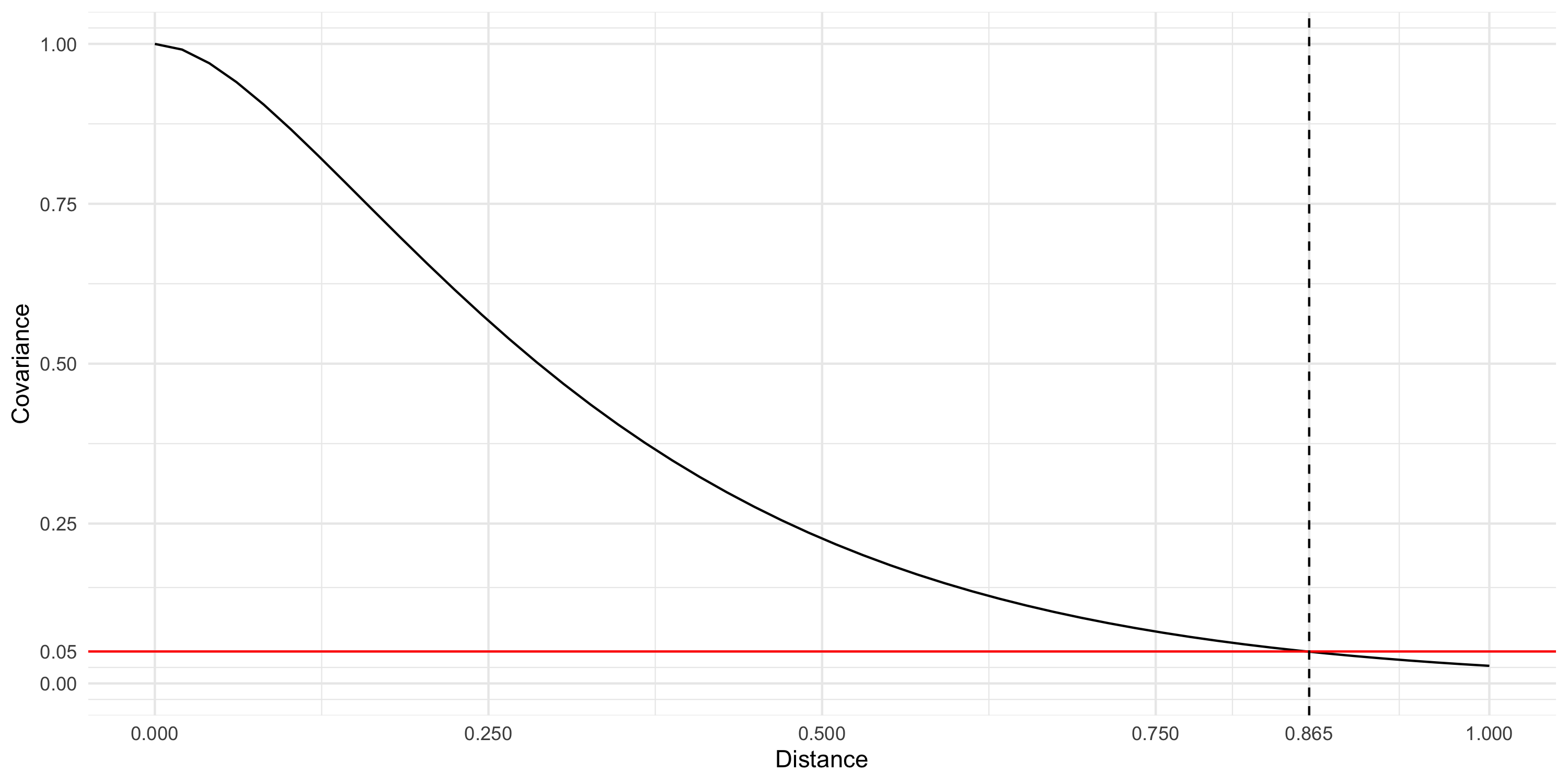
what is the distance between locations at which correlation falls under 0.05?
The second question is also called the effective range
Effective range
The distance d such that Cor(d)=0.05 where Cor(\cdot) is the implied correlation function.
Example: exponential correlation function Cor(d) = \exp\{ -\phi d \}.
Is this an exponential correlation plot?
Some ways to obtain other covariance functions
Sum: if C_1(s, s') and C_2(s, s') are two covariance functions, then C(s, s') = C_1(s, s') + C_2(s, s') is also a valid covariance function
Product: if C_1(s, s') and C_2(s, s') are two covariance functions, then C(s, s') = C_1(s, s') \cdot C_2(s, s') is also a valid covariace function
Some ways to obtain other covariance functions: cont’d
If w_1(\cdot) \sim GP(0, C_1(\cdot, \cdot)) is independent of w_2(\cdot) \sim GP(0, C_2(\cdot, \cdot)) then w(\cdot) = w_1(\cdot) + w_2(\cdot) \sim GP(0, C_1(\cdot, \cdot) + C_2(\cdot, \cdot))
If w_1(\cdot) \sim GP(0, C_1(\cdot, \cdot)) is independent of w_2(\cdot) \sim GP(0, C_2(\cdot, \cdot)) then w(\cdot) = w_1(\cdot) \cdot w_2(\cdot) is such that Cov(w(\cdot)) = C(\cdot, \cdot) = C_1(\cdot, \cdot) \cdot C_2(\cdot, \cdot). But notice w(\cdot) is not a GP.
We see that if w(\cdot) \sim GP(0, C) then we can write
w(\cdot) = v(\cdot) + \varepsilon(\cdot) where v(\cdot) is a GP with exponential covariance and \varepsilon(\cdot) is a white noise process
Some ways to obtain other covariance functions: cont’d
Direct sum: if C_1(s_1, s_1') is a covariance function on domain D_1 and C_2(s_2, s_2') is a covariance function on domain D_2 then C(s, s') = C_1(s_1, s_1') + C_2(s_2, s_2') is a covariance function on the domain D_1 \times D_2.
Example:
Suppose D_1=D \subset \Re^2 is the usual spatial domain, D_2=T\subset \Re is the time domain.
Let u(s,t) = w(s) + v(t) where w(\cdot) and v(\cdot) are GPs defined on D and T, respectively, we have that u(s,t) is a GP on D \times T.
In other words, this is a simple way to define a spatiotemporal process
Tensor product: if C_1(s_1, s_1') is a covariance function on domain D_1 and C_2(s_2, s_2') is a covariance function on domain D_2 then C(s, s') = C_1(s_1, s_1') \cdot C_2(s_2, s_2') is a covariance function on the domain D_1 \times D_2
Examples of non-stationary covariances
Paciorek and Schervish (2006), based on the Matern model:
C(s_i, s_j) = \sigma^2 \frac{2^{1-\nu}}{\Gamma(\nu)} |\Sigma_i|^{-\frac{1}{4}} |\Sigma_j|^{\frac{1}{4}} \left| \frac{\Sigma_i + \Sigma_j}{2} \right|^{-\frac{1}{2}} \left(2 \sqrt{\nu Q_{ij}} \right)^{\nu} K_{\nu}\left(2 \sqrt{\nu Q_{ij}} \right) where Q_{ij} = (s_i - s_j)^T \left(\frac{\Sigma_i + \Sigma_j}{2} \right)^{-1}(s_i - s_j) and \Sigma_i = \Sigma(x_i) is called the kernel matrix.
Another example
C(s_i, s_j) = \exp\{ \phi(s_i) + \phi(s_j) \} M(s_i, s_j) where M(s_i, s_j) is a Matern covariance function and \phi(x) = c_1 \phi_1(x) + \dots + c_p \phi_p(x).
Here, \phi_r(x) is the rth basis function (of a total of p) evaluated at x, and c_r,\ r=1, \dots p are nonstationary variance parameters
Why are these nonstationary?
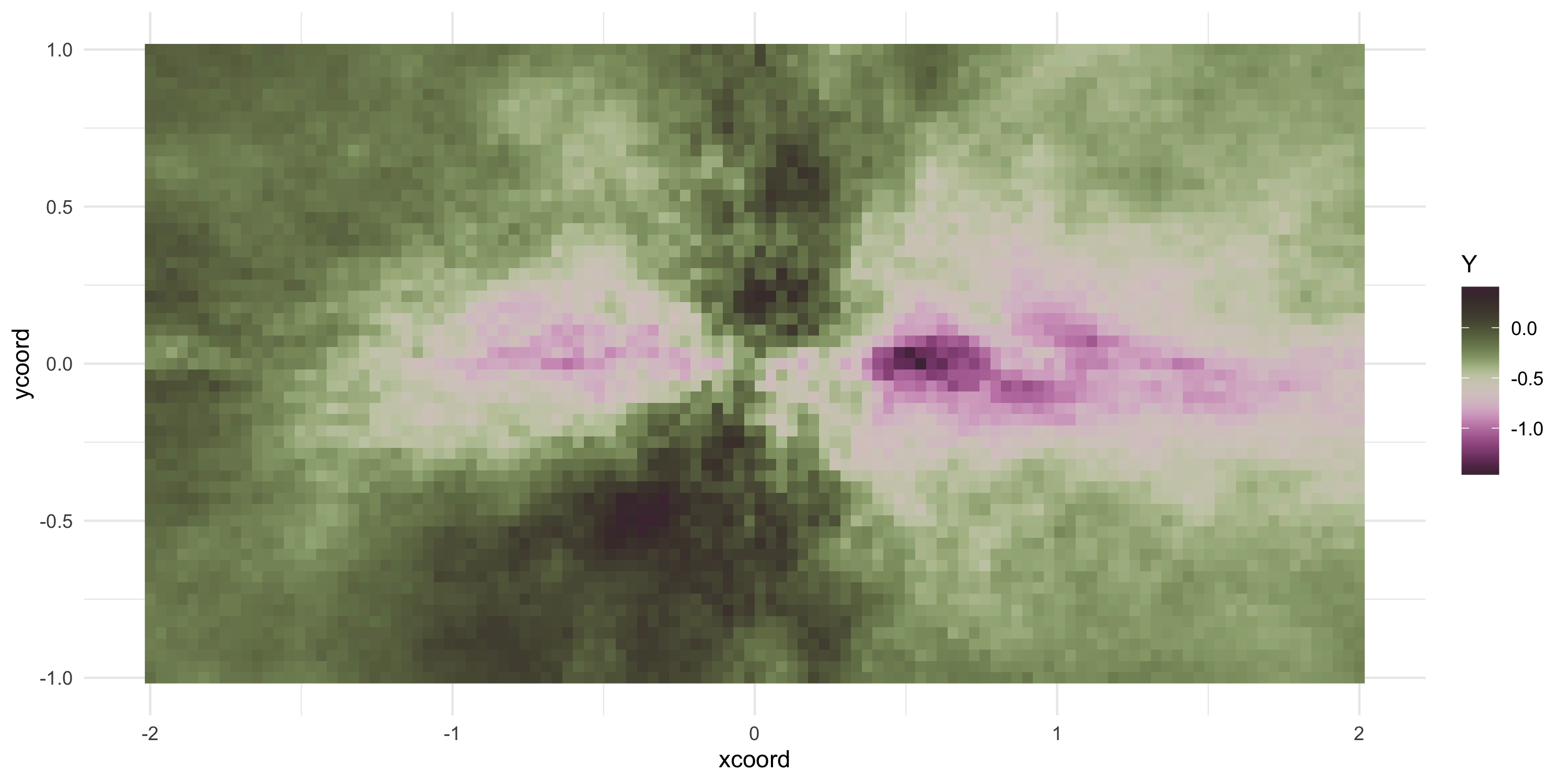
Paciorek and Schervish 2006: examples
Paciorek and Schervish 2006: simulated data examples
Paciorek and Schervish 2006: simulated data examples
Extending GPs to multivariate data
We have considered GPs for univariate data
Univariate data: one random variable for each spatial location
Multivariate data: one random vector for each spatial location
Nothing in our discussion changes when we want to define a multivariate GP
Except: we need to define a cross-covariance function
Cross-covariance function: not only defines covariance in space, but also across variables
C(\ell_i, \ell_j) is a matrix valued function. The (r,s) element of C(\ell_i, \ell_j) is the covariance between the r variable measured at location \ell_i and the s variable measured at location \ell_j
See book Chapter 9.2.
More on this later.
First steps in modeling data via GPs
Probability models for point-referenced spatial data interpret observations as realizations of a set of spatially-indexed random variables
At each observed spatial location, we “see” 1 realization of a random variable
All random variables are dependent on each other
We assume that dependence generally decays with distance
We assume that a multivariate Gaussian distribution is appropriate for our collection of random variables
We assume a covariance model with a small number of parameters
We aim to learn about the covariance model using the observed data
Everything is in place to apply our simple GP model to point-referenced data