library(tidyverse)
library(sf)
library(rnaturalearth)
mainmap <- ne_states(country = c("united states of america", "canada"), returnclass = "sf")
michiganplus <- mainmap %>% dplyr::filter(name %in% c("Illinois", "Michigan", "Wisconsin", "Ontario"))
ggplot() +
geom_sf(data = michiganplus, fill = "white", color = "black") +
coord_sf(ylim = c(42, 46), xlim = c(-87, -82)) + # reduce visualization to smaller area
theme_minimal()Types of Spatial Data
Spatial Statistics - BIOSTAT 696/896
Three broad categories
- Point-referenced data
- Point pattern data
- Areal data
Point-referenced data: example
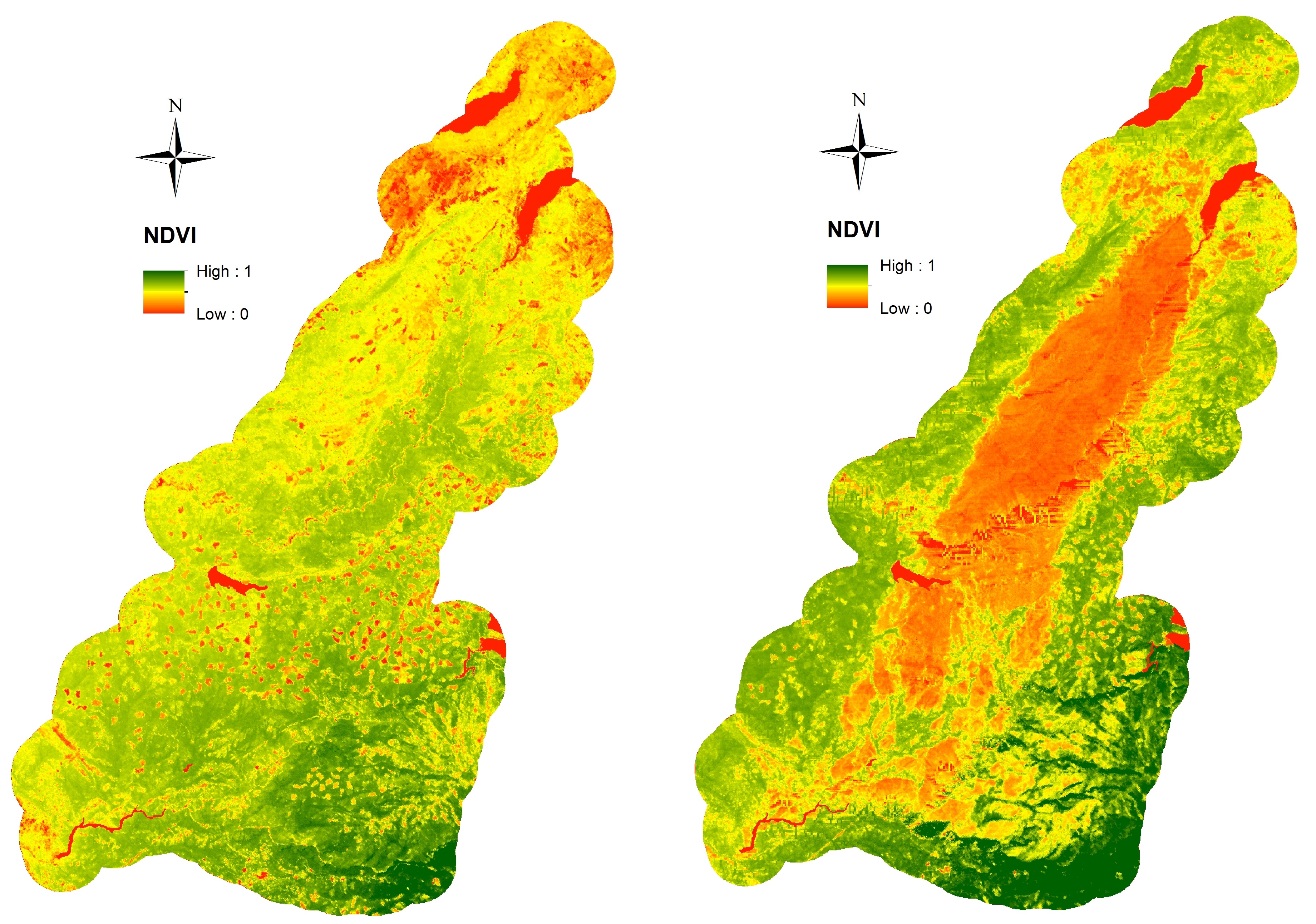
Vegetation in a region of California before (left) and after (right) a forest fire
Point-pattern data: example
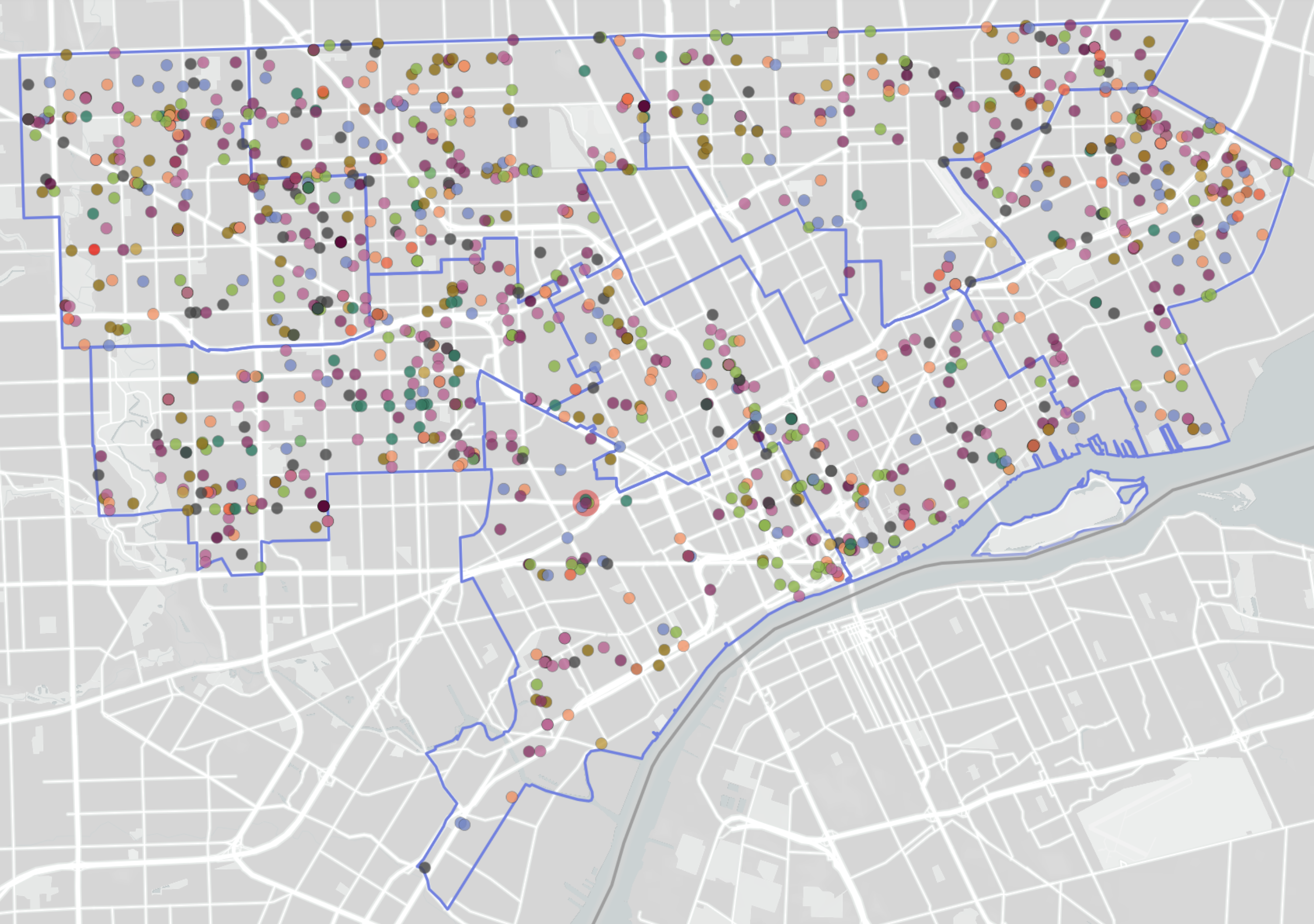
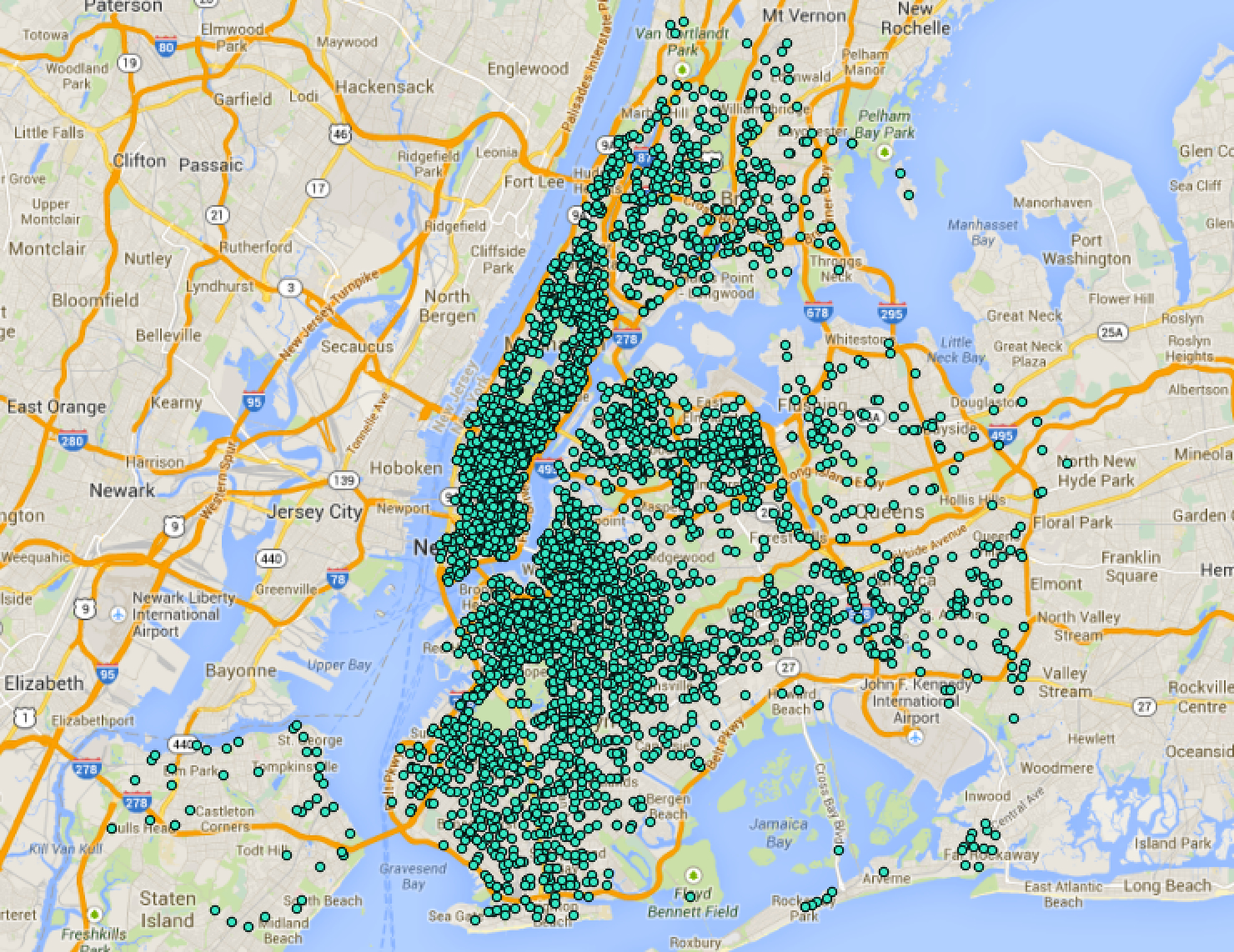
- What is the spatial domain in each case?
Areal data: example
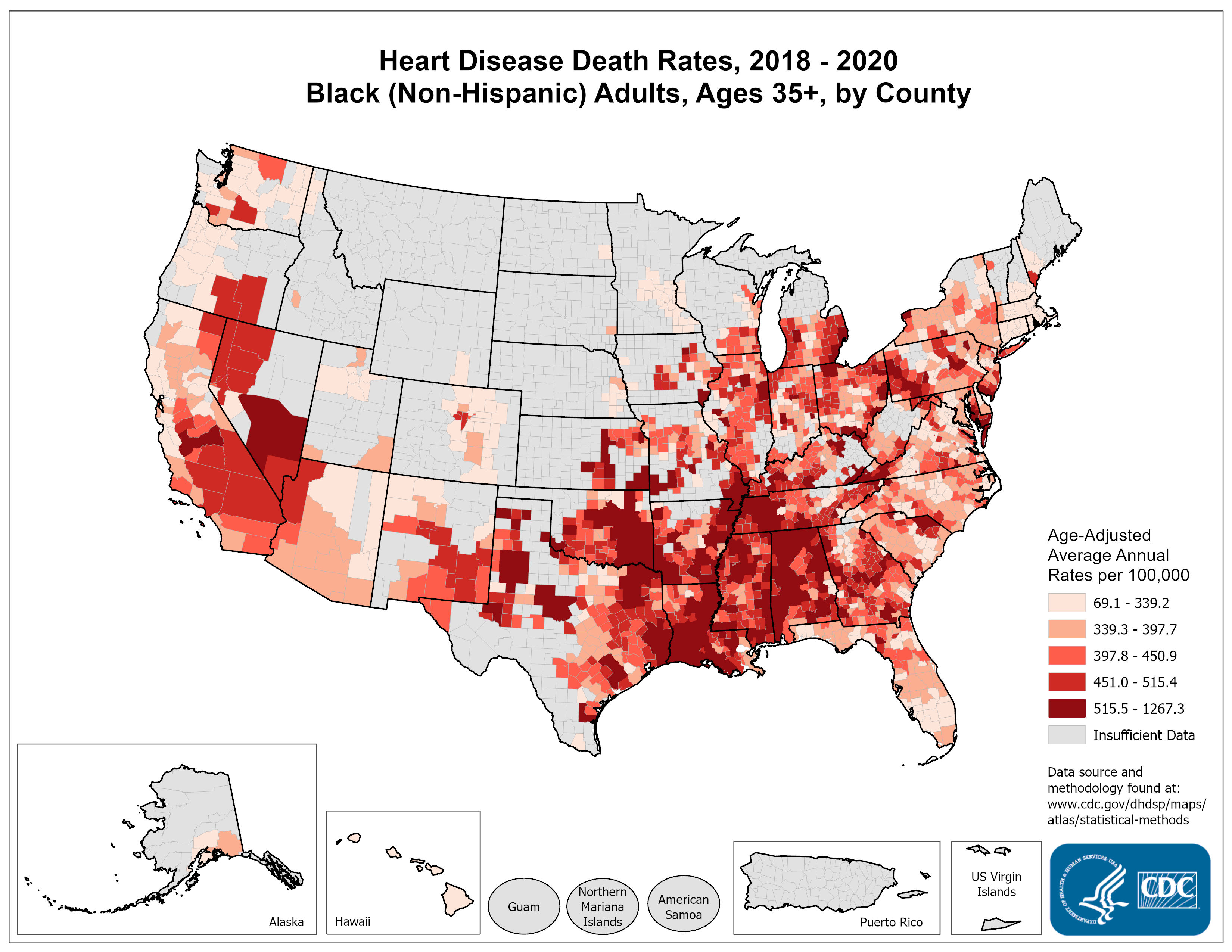
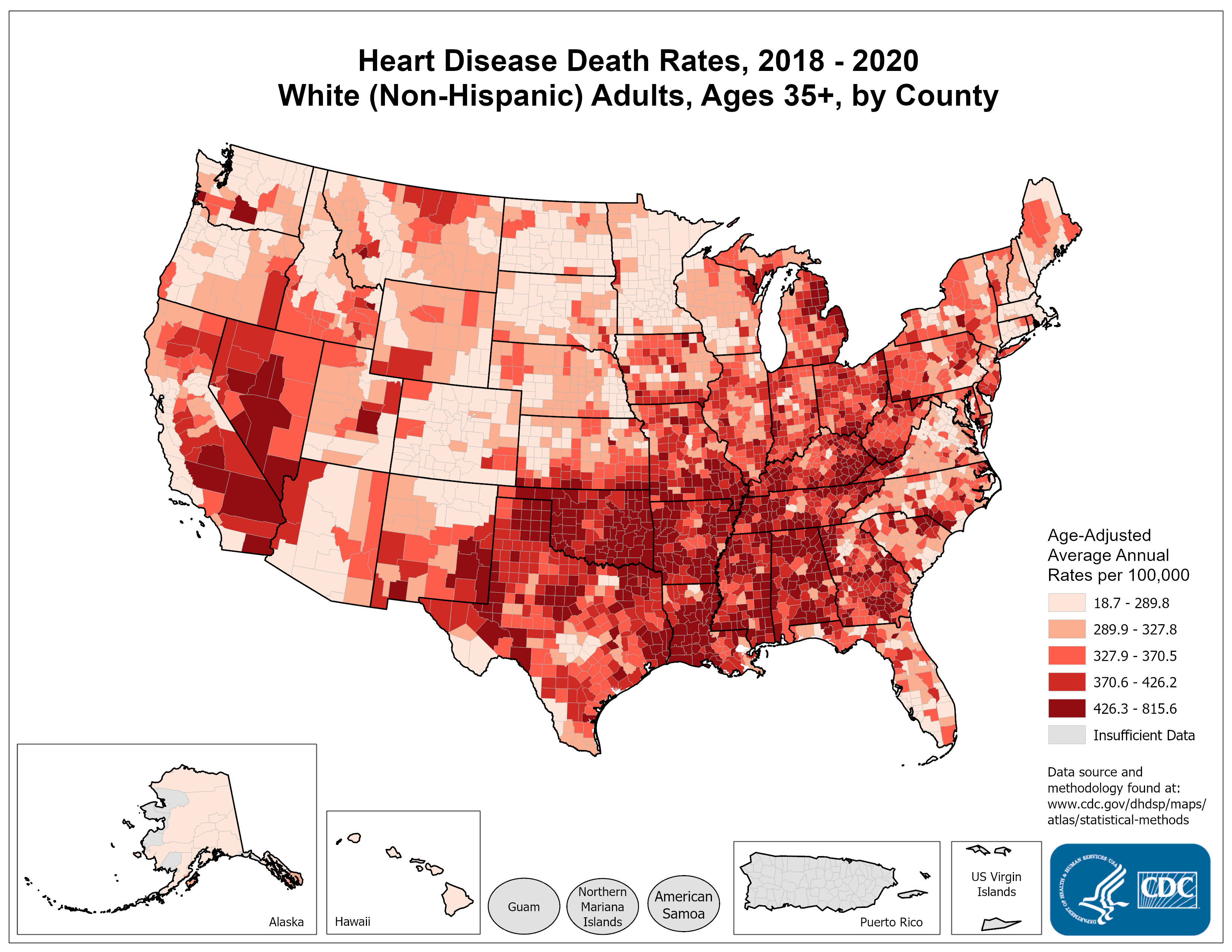
- What do you notice?
- What are some questions that these data may help address?
- Criticize this slide. Is the side-by-side clear?
Discussion
- ChatGPT says “real estate data” (e.g. location of houses for sale today) is a point pattern
- Is it really?
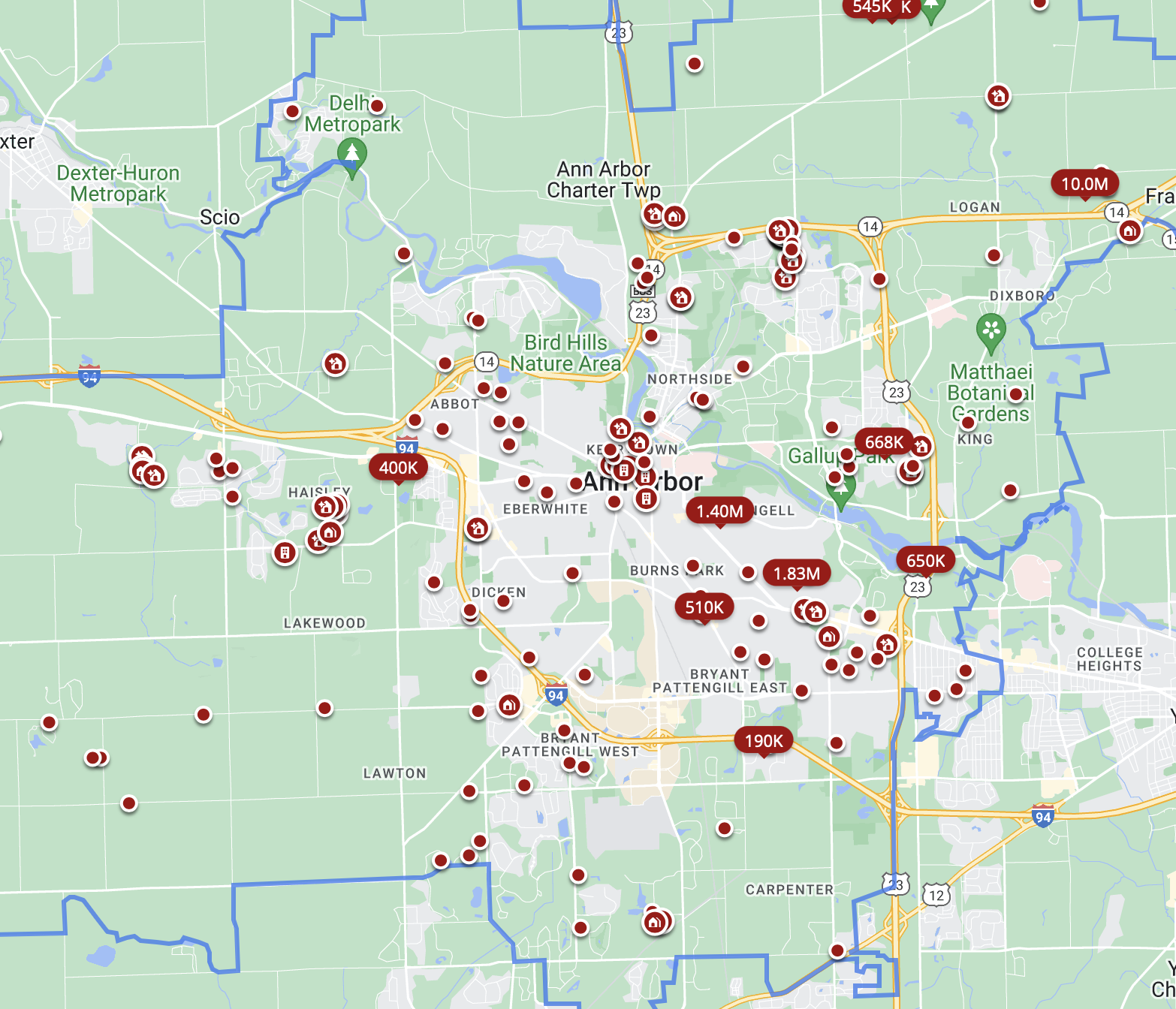
Discussion

- We may treat these data as a point pattern
- But the spatial domain is the union of non-intersecting regions
- Not very clear-cut distinction
Visualization
Example data: vegetation greenness over Michigan (minus UP)
Visualization
Now plot the data on top of the map
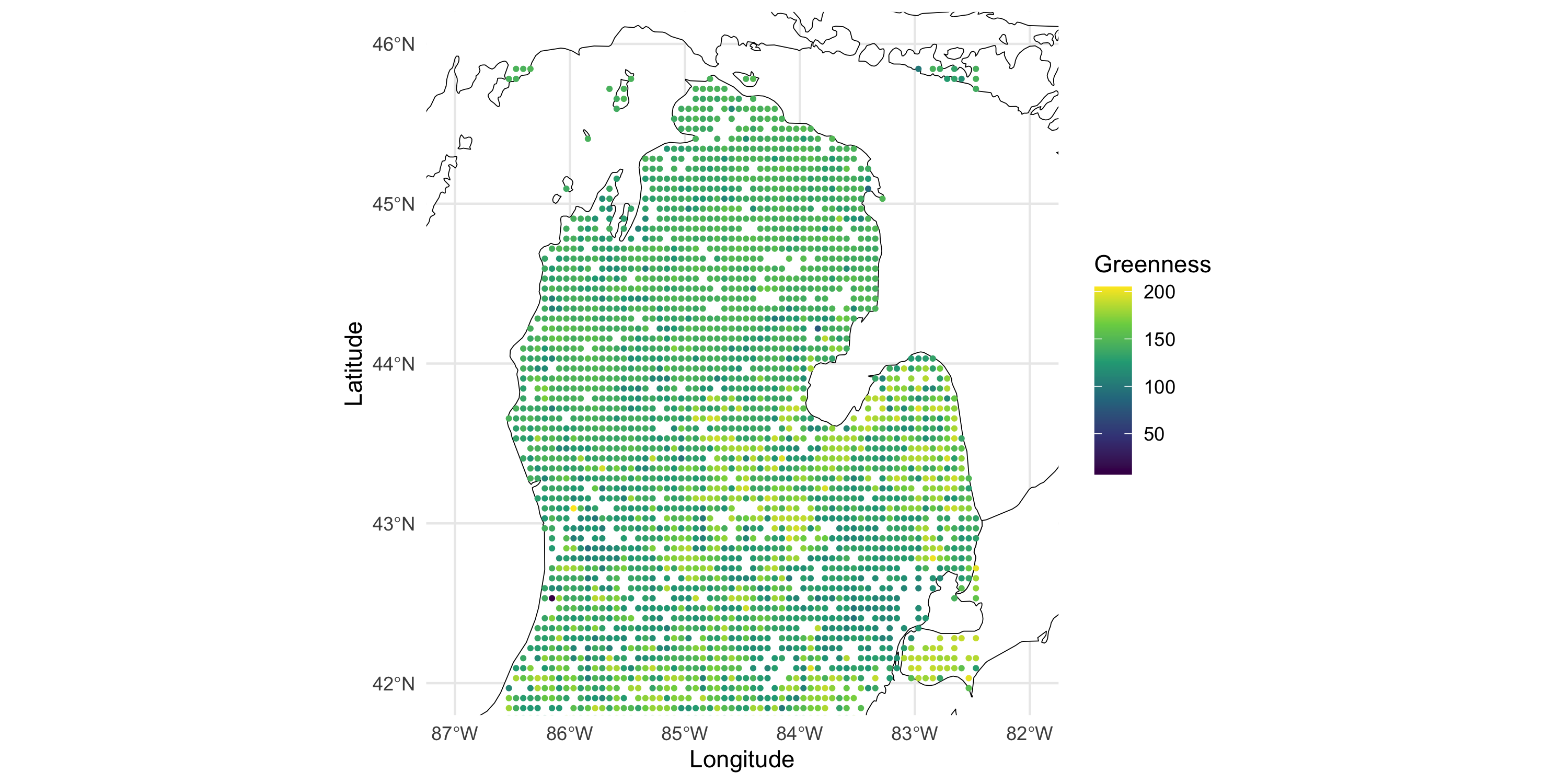
Visualization
Other variables in the same dataset: GDD (growing degree day)
colnames(df)[3:4] <- c("gdd0800", "gdd0900")
df_long <- df %>% dplyr::select(Longitude, Latitude, contains("gdd")) %>%
tidyr::pivot_longer(cols=c(-Longitude, -Latitude), names_to = "GDD degree", values_to = "GDD value")
ggplot() +
geom_sf(data = michiganplus, fill = "white", color = "black") +
coord_sf(ylim = c(42, 46), xlim = c(-87, -82)) +
geom_point(data = df_long, aes(x=Longitude, y=Latitude, color=`GDD value`), size=.7) +
scale_color_viridis_c() +
facet_wrap(~ `GDD degree`, nrow=4) +
theme_minimal()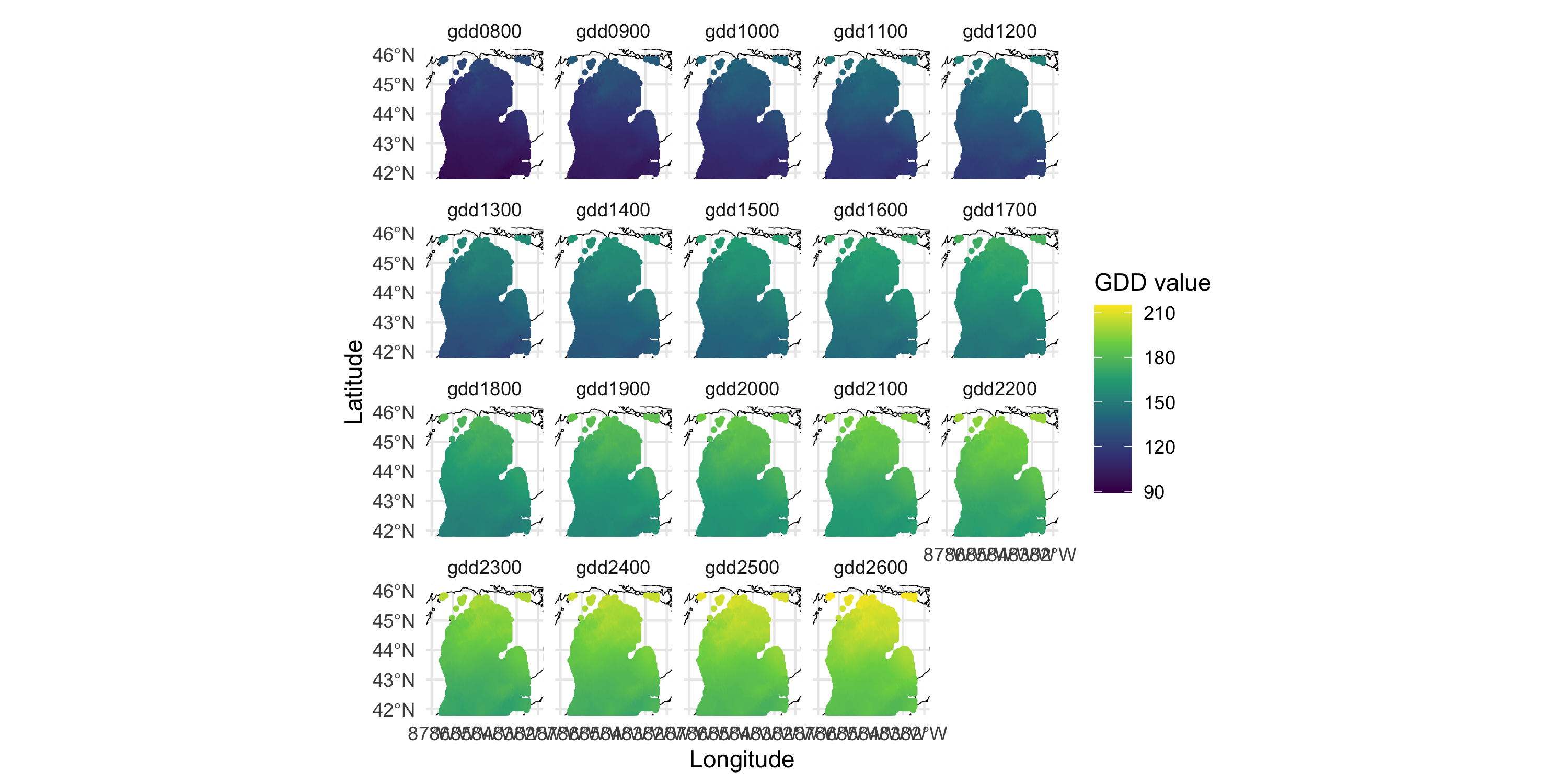
Visualization
Other variables in the same dataset: terrain forest type
dc_MixedForest
dc_DeciduousForest 0 1
0 2904 77
1 27 0Same location may have multiple forest types, apparently. Therefore, must use multiple panels
df_long <- df %>% dplyr::select(Longitude, Latitude, contains("dc_")) %>%
tidyr::pivot_longer(cols=c(-Longitude, -Latitude), names_to = "Forest type", values_to = "value") %>%
dplyr::filter(value == 1)
ggplot() +
geom_sf(data = michiganplus, fill = "white", color = "black") +
coord_sf(ylim = c(42, 46), xlim = c(-87, -82)) +
geom_point(data = df_long, aes(x=Longitude, y=Latitude, color=factor(value)), size=2, shape=17) +
scale_color_manual(values="darkgreen") +
facet_wrap(~ `Forest type`) +
theme_minimal() +
theme(legend.position="none")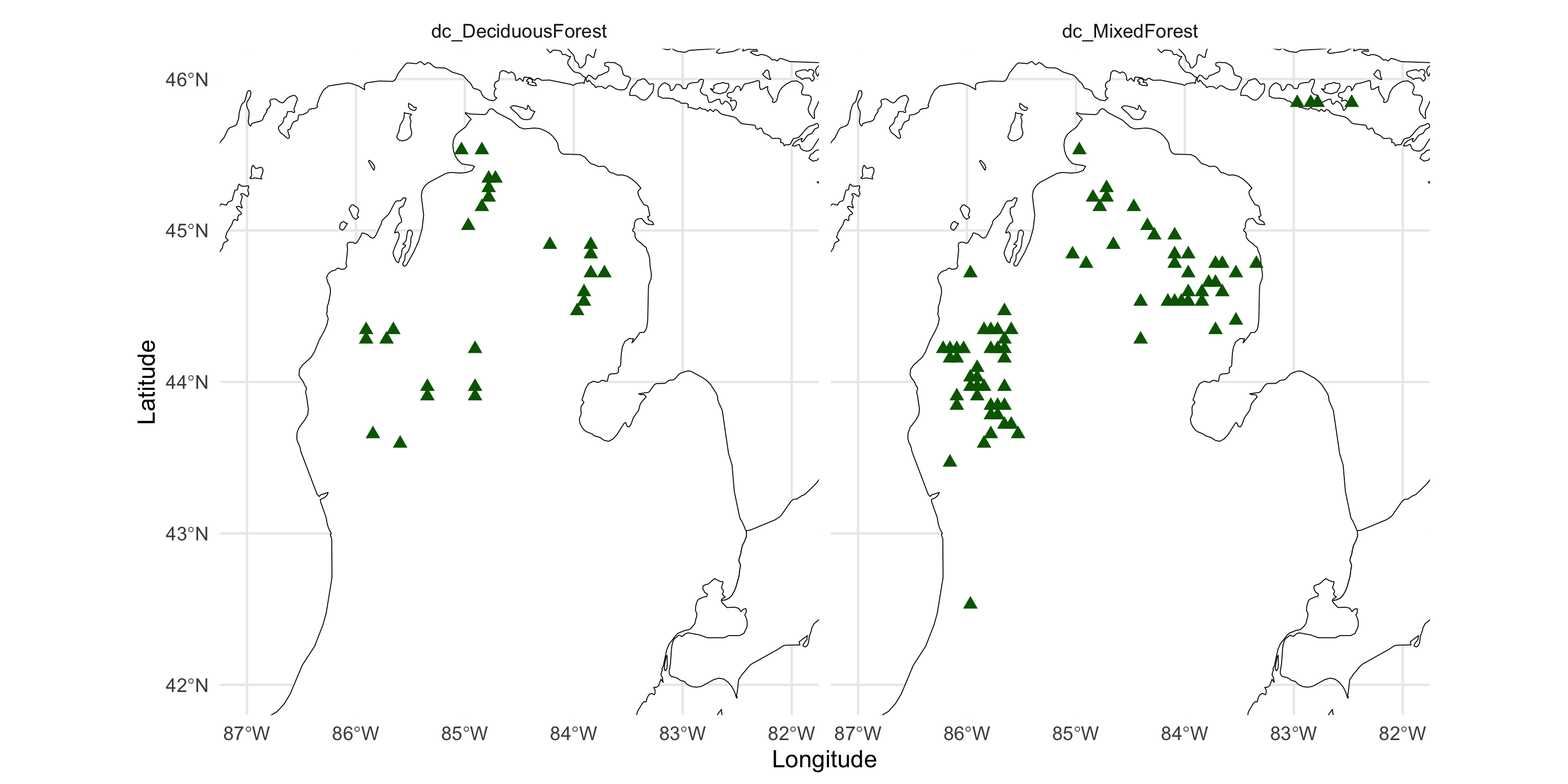
Visualization: choosing colors
- Color scales are important for interpreting and differentiating
- Remember not everyone sees color the same way!

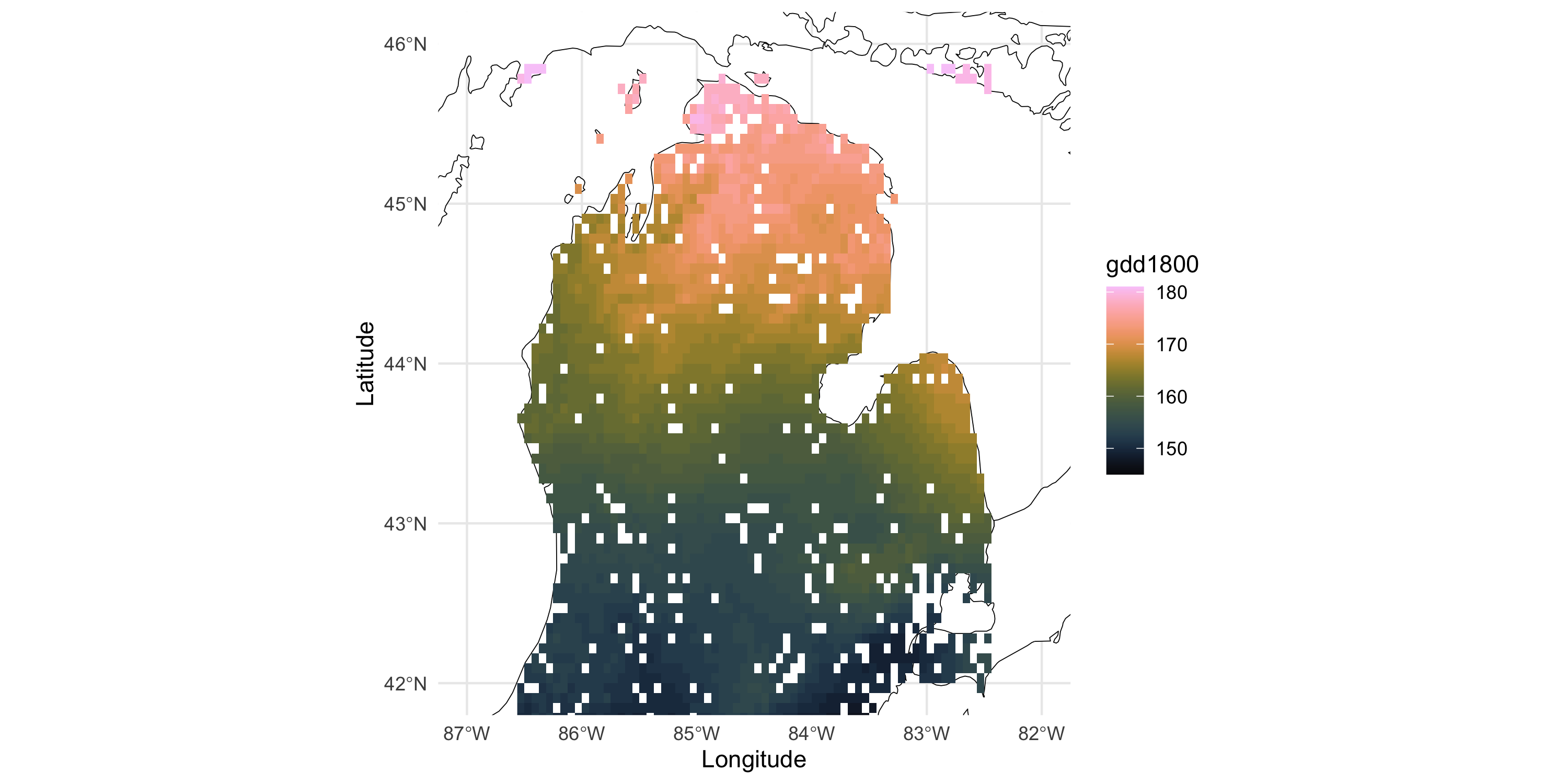
Visualization: choosing colors
- Also, because this dataset is on a regular grid of coordinates, we can plot a raster image
- Convenient: no need to choose point size, more efficient than
geom_tile
Management and visualization of areal data
- Also need a FIPS-State abbreviation table
state_fips <- tidycensus::fips_codes %>%
dplyr::select(state, state_code) %>%
unique() %>%
# call the columns with the names they have in the respective datasets
dplyr::rename(STATEFP = state_code, LocationAbbr = state)
counties <- counties %>%
left_join(state_fips) %>%
dplyr::rename(LocationDesc = NAME)Make into sf object and plot the map
df_local <- df %>%
left_join(counties, by = c("LocationAbbr", "LocationDesc")) %>%
st_as_sf()
ggplot(data=df_local %>%
dplyr::filter(Stratification1 == "Overall", Stratification2 == "Overall")) +
geom_sf(aes(fill=Data_Value)) +
theme_minimal() +
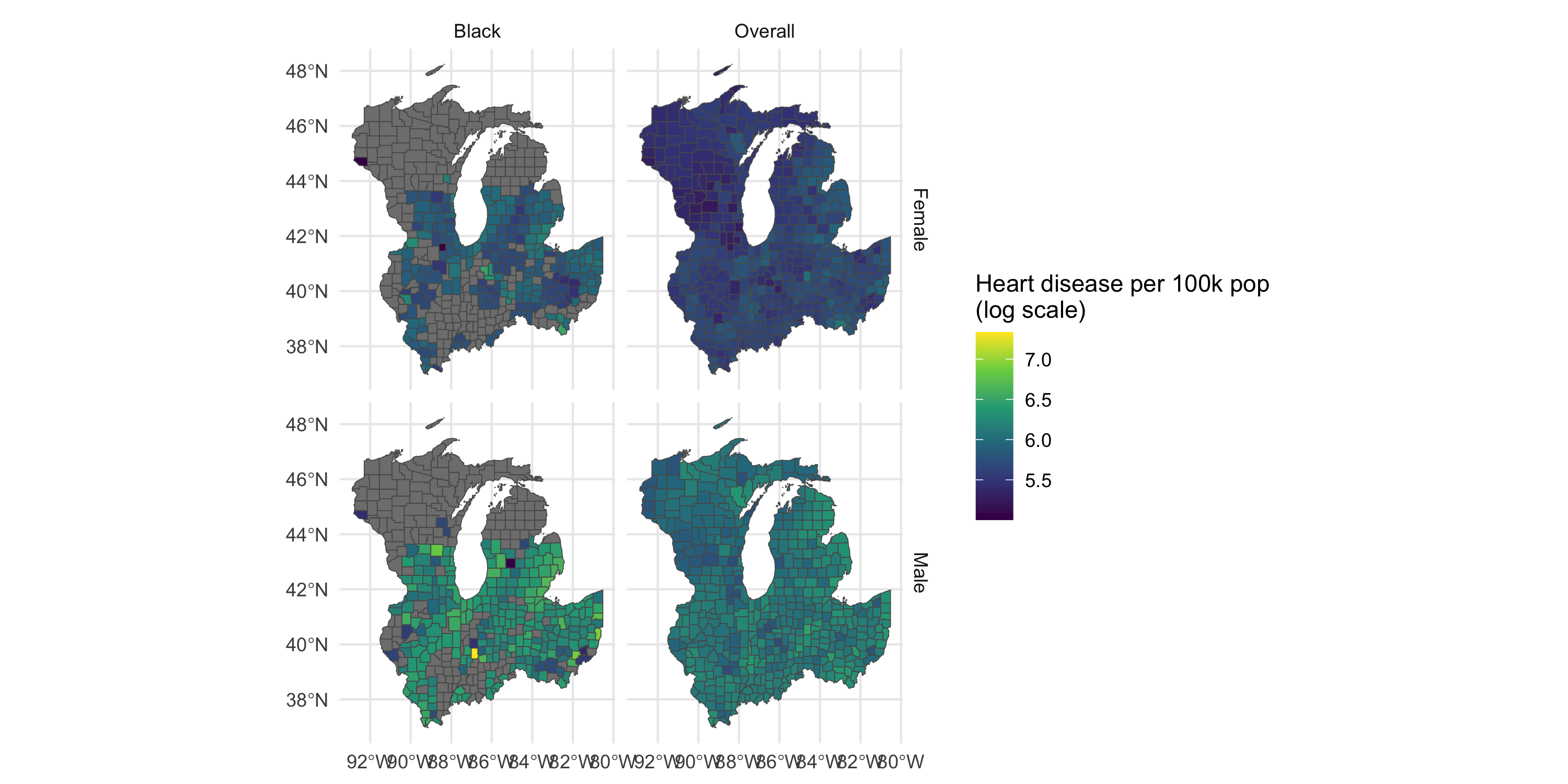
labs(fill = "Heart disease per 100k pop") +
scale_fill_viridis_c()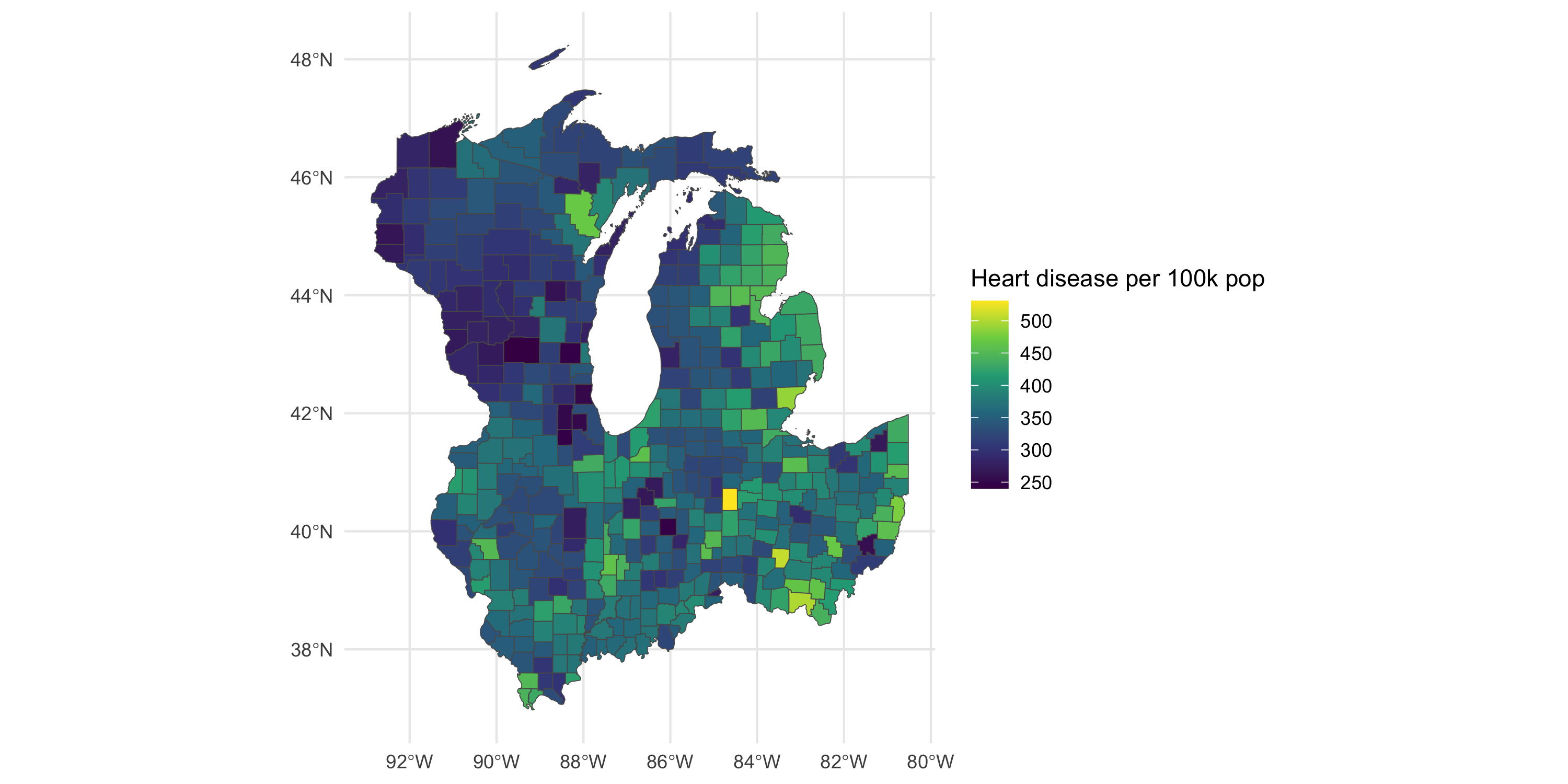
Management and visualization of areal data
Plot map by gender
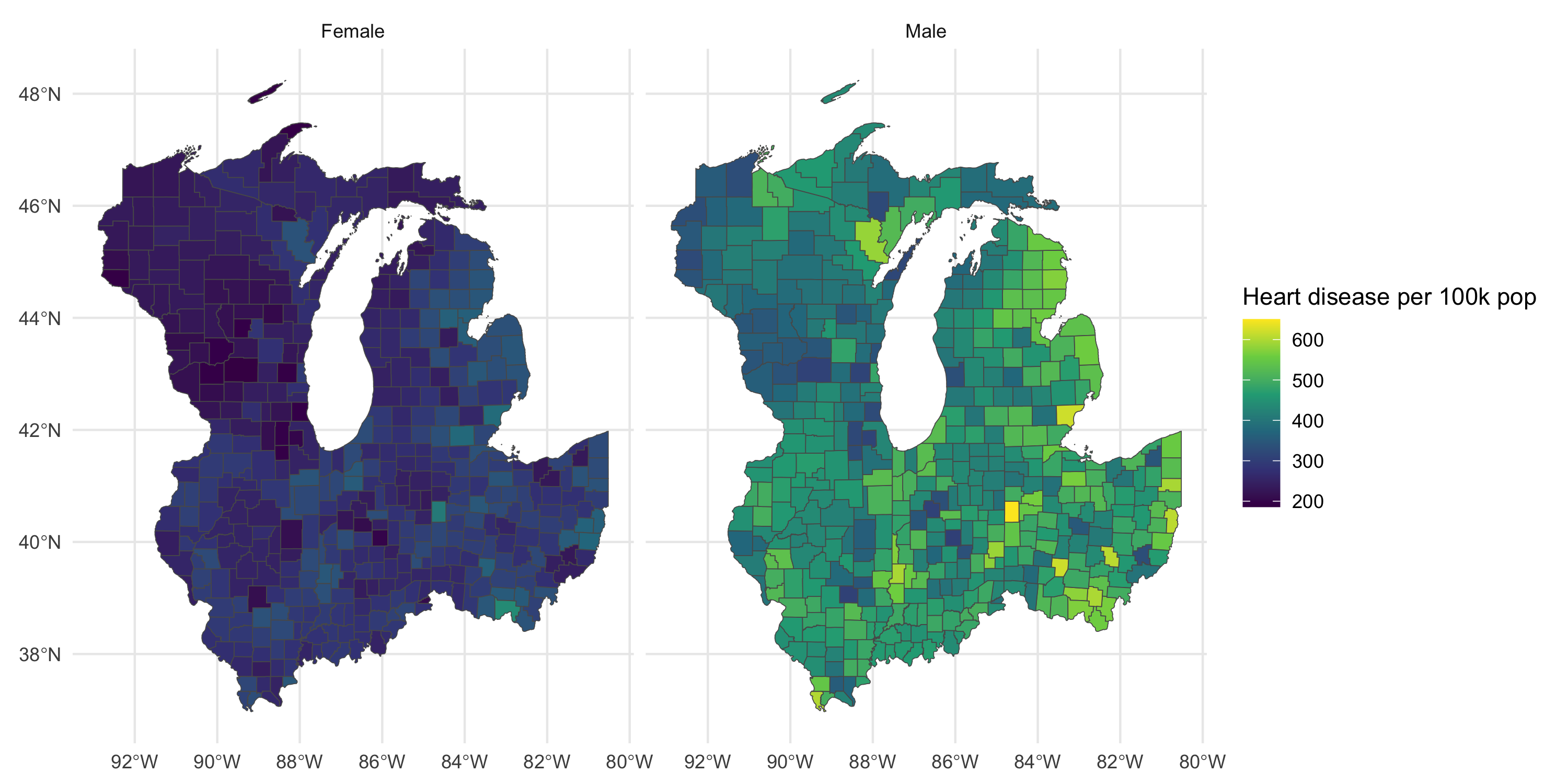
Management and visualization of areal data
Plot map by gender and race/ethnicity
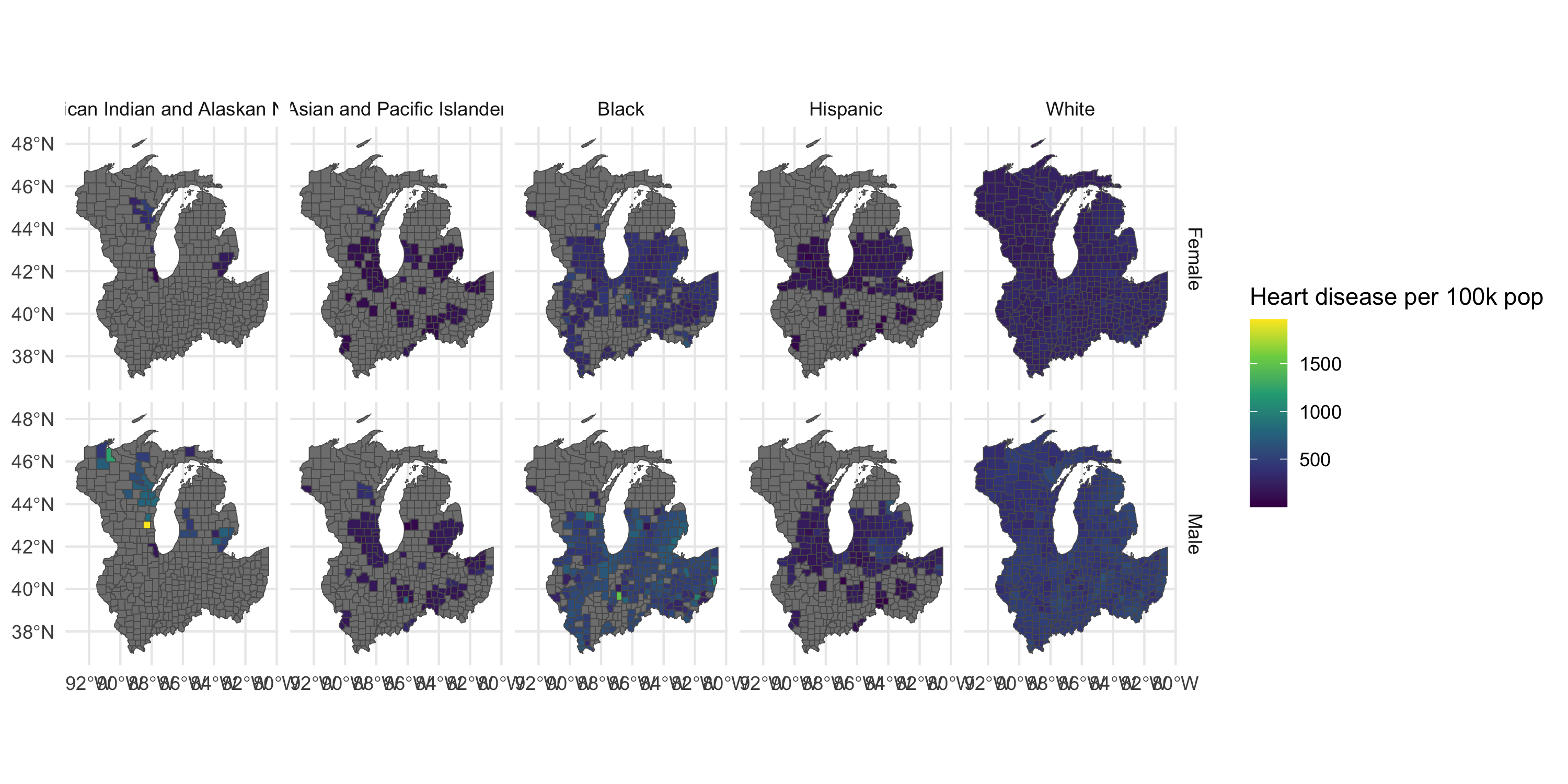
Management and visualization of areal data
Restrict and transform